1 prometheus介绍
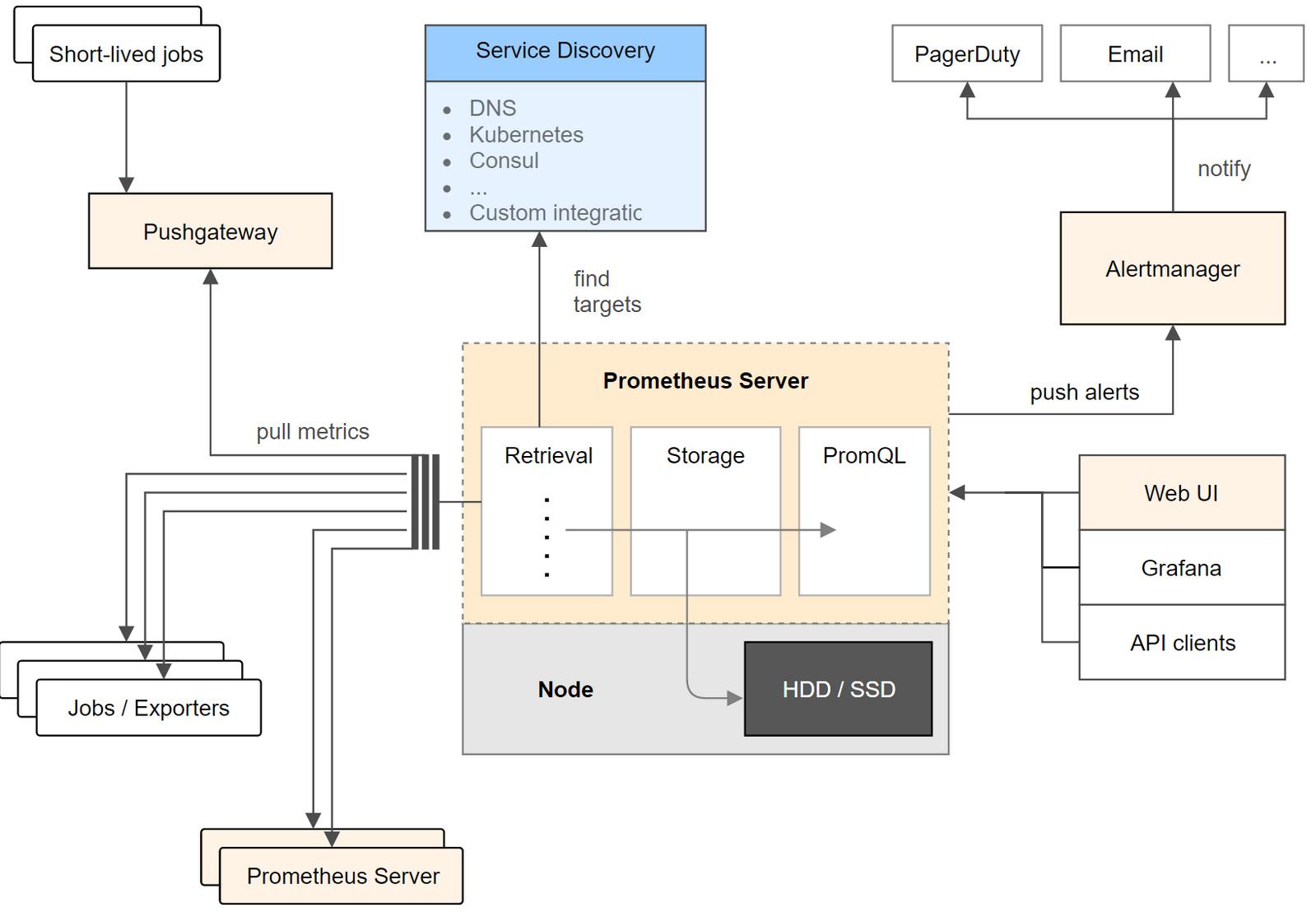
Prometheus是一个云原生计算基础项目,是一个系统和服务监控系统。它以给定的时间间隔从配置的目标收集指标,评估规则表达式,显示结果,并且如果观察到某些条件为真,则可以触发警报。
prometheus的主要区别特征是:
- 一个多维数据模型(时间序列由指标名称定义和设置键/值尺寸)
- 一个灵活的查询语言来利用这一维度
- 不依赖于分布式存储; 单个服务器节点是自治的
- 时间序列集合通过HTTP 上的拉模型进行
- 通过中间网关支持推送时间序列
- 通过服务发现或静态配置发现目标
- 多种图形和仪表板支持模式
- 支持分层和水平联合
2 prometheus安装
2.1 在docker安装prometheus
prometheus的配置文件prometheus.yml内容如下:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
docker-compose.yml的内容如下:
version: "3"
services:
prometheus:
container_name: prometheus
image: prom/prometheus:v2.11.1
ports:
- 9090:9090
command:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prom-data:/prometheus
volumes:
prom-data:
driver: local
启动prometheus:
docker-compose up -d
启动后在浏览器打开 http://192.168.101.88:9090 ,进入prometheus界面,只是没有数据而已。
2.2 采集node节点资源、容器信息、grafana数据可视化
一般不建议使用docker安装node-exporter,如果在docker安装node-exporter需要把节点信息映射到容器中。
prometheus的配置文件prometheus.yml内容如下:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
#- alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
#- "/etc/prometheus/rules/*.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090','cadvisor:8080','node-exporter:9100']
grafana的配置文件datasource.yaml内容如下:
# config file version
apiVersion: 1
# list of datasources that should be deleted from the database
deleteDatasources:
- name: Graphite
orgId: 1
datasources:
- name: Prometheus
type: prometheus
access: proxy
isDefault: true
url: http://prometheus:9090
# don't use this in prod
editable: true
docker-compose.yml文件内容如下:
version: "3"
services:
prometheus:
container_name: prometheus
restart: always
image: prom/prometheus:v2.11.1
ports:
- 9090:9090
command:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
volumes:
- ./config/prometheus.yml:/etc/prometheus/prometheus.yml
- prom-data:/prometheus
networks:
- prom-net
# node节点资源信息
node-exporter:
container_name: node-exporter
restart: always
image: prom/node-exporter:latest
ports:
- 9100:9100
networks:
- prom-net
# 容器相关信息
cadvisor:
container_name: cadvisor
restart: always
image: google/cadvisor:latest
ports:
- 9101:8080
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
networks:
- prom-net
# 数据可视化
grafana:
container_name: grafana
image: grafana/grafana:6.2.5
restart: always
ports:
- "3003:3000"
volumes:
- ./grafana/datasource.yaml:/etc/grafana/provisioning/datasources/datasource.yaml
- grafana-data:/var/lib/grafana
networks:
- prom-net
#environment:
# - GF_SECURITY_ADMIN_PASSWORD=123456
volumes:
prom-data:
driver: local
grafana-data:
driver: local
networks:
prom-net:
driver: bridge
启动prometheus:
docker-compose up -d
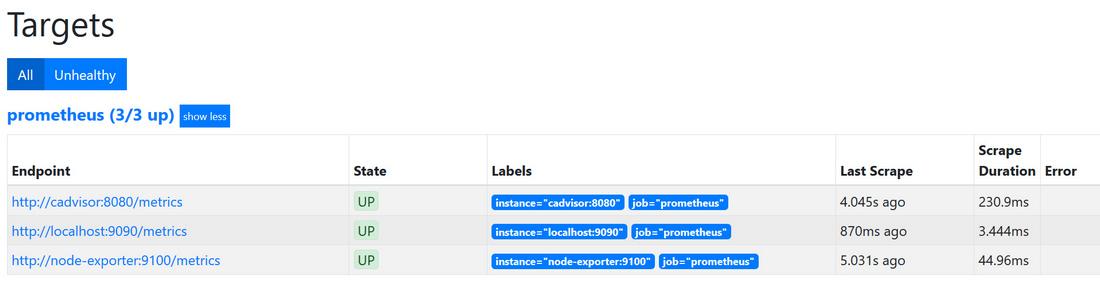
启动后在浏览器打开 http://192.168.101.88:9090 ,进入prometheus界面,点击菜单status下Targets查看已经生效的Targets,如下图所示:
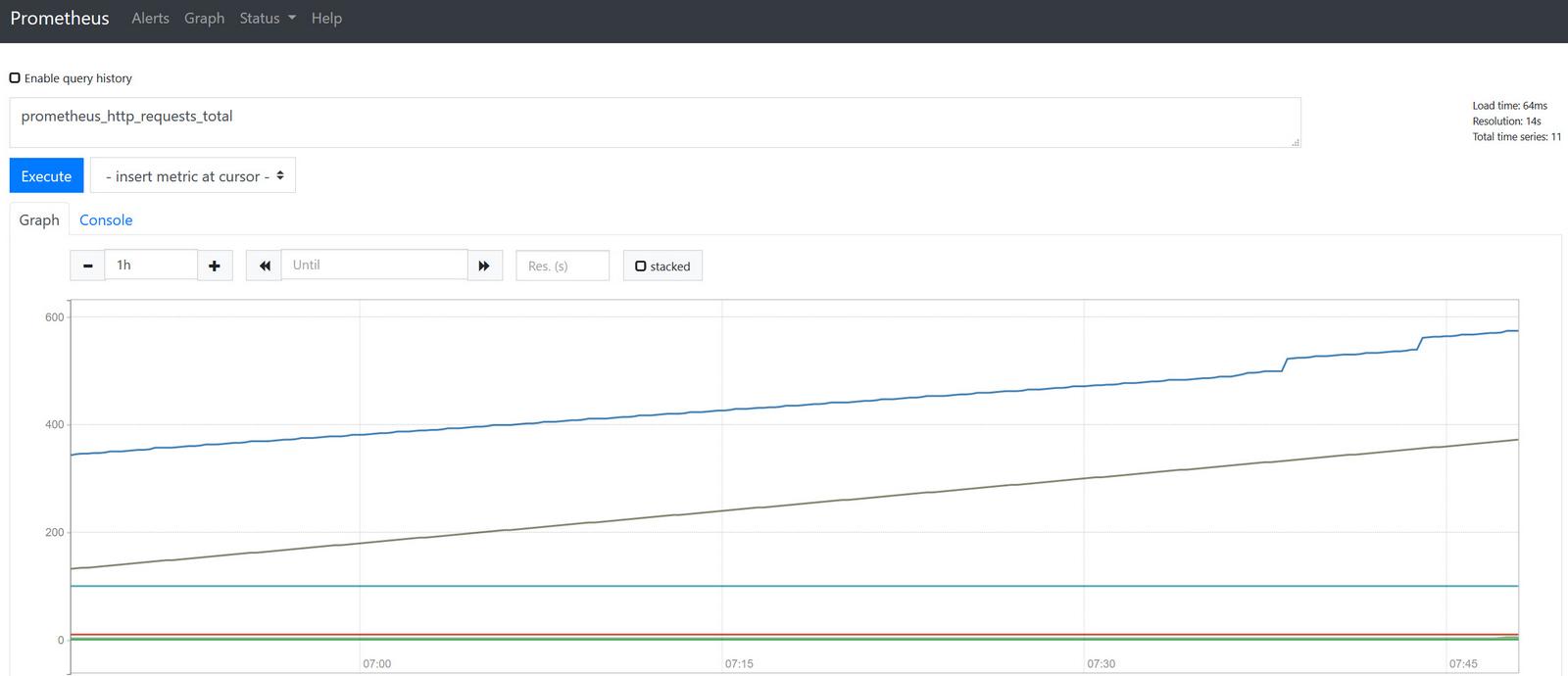
输入关键字prometheus_http_requests_total可以查询请求prometheus数据,如下图所示:
在浏览器打开 http://192.168.101.88:3003 ,默认登陆账号和密码都是admin,由于grafana配置文件已经设置了prometheus的数据源,不需要再添加数据源,如果没有配置数据源,先要添加数据源。
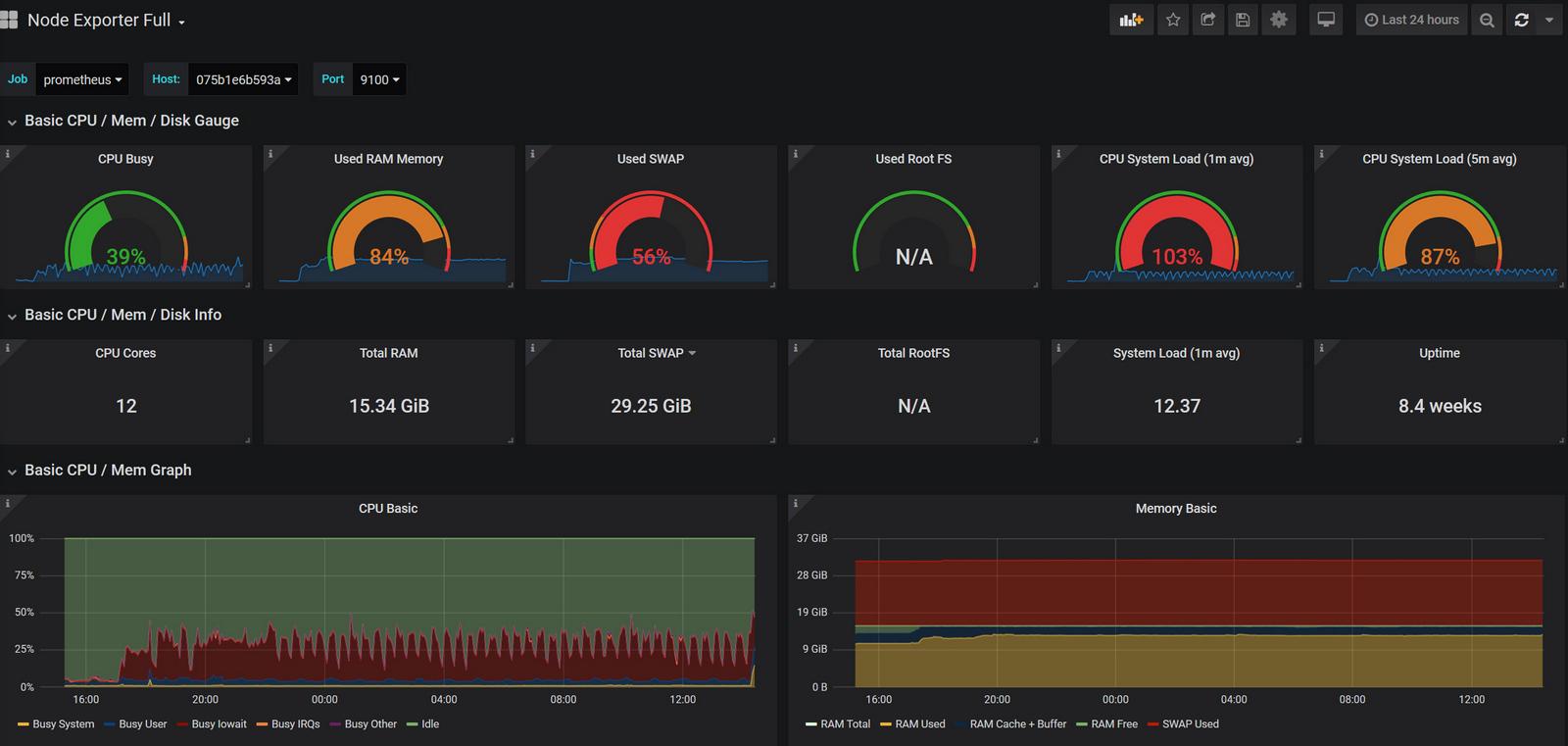
在浏览器打开 https://grafana.com/grafana/dashboards ,搜索相应的dashboard,使用grafana编号为1860和8919能够满足node-export(系统)的数据可视化了,使用grafana编号893(容器)能够满足cadvisor的数据可视化,具体使用方法进入grafana界面,鼠标移动到左边菜单栏的+号,选择import,输入编号1860,鼠标点击任意其它地方,选择prometheus数据源后导入即可,最后效果图如下:
grafana免密码登录设置
修改配置文件,允许匿名登录enabled = true,匿名登录角色改为Admin
[auth.anonymous]
# enable anonymous access
enabled = true
# specify role for unauthenticated users
org_role = Admin
3 PromQL的基础知识
指标(Metric)的通用格式:
<metric name>{<label name>=<label value>, ...}
指标的名称(metric name)可以反映被监控样本的含义(比如,http_requeststotal - 表示当前系统接收到的HTTP请求总量)。指标名称只能由ASCII字符、数字、下划线以及冒号组成并必须符合正则表达式[a-zA-Z:][a-zA-Z0-9_:]*。
标签(label)反映了当前样本的特征维度,通过这些维度Prometheus可以对样本数据进行过滤,聚合等。标签的名称只能由ASCII字符、数字以及下划线组成并满足正则表达式[a-zA-Z][a-zA-Z0-9]*。
其中以__作为前缀的标签,是系统保留的关键字,只能在系统内部使用。标签的值则可以包含任何Unicode编码的字符。在Prometheus的底层实现中指标名称实际上是以 __name__=
api_http_requests_total{method="POST", handler="/messages"}
{__name__="api_http_requests_total",method="POST", handler="/messages"}
示例:
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
node_load1 3.0703125
node_cpu和node_load1表明了当前指标的名称、大括号中的标签则反映了当前样本的一些特征和维度、浮点数则是该监控样本的具体值。
3.1 Metrics类型
Prometheus定义了4中不同的指标类型(metric type):
- Counter(计数器)
- Gauge(仪表盘)
- Histogram(直方图)
- Summary(摘要)
在Exporter返回的样本数据中,其注释中也包含了该样本的类型。例如:
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
(1) Counter:只增不减的计数器
Counter类型的指标其工作方式和计数器一样,只增不减(除非系统发生重置)。常见的监控指标,如http_requests_total,node_cpu都是Counter类型的监控指标。 一般在定义Counter类型指标的名称时推荐使用_total作为后缀。
Counter是一个简单但有强大的工具,例如我们可以在应用程序中记录某些事件发生的次数,通过以时序的形式存储这些数据,我们可以轻松的了解该事件产生速率的变化。PromQL内置的聚合操作和函数可以用户对这些数据进行进一步的分析:
# 通过rate()函数获取HTTP请求量的增长率:
rate(http_requests_total[5m])
# 查询当前系统中,访问量前10的HTTP地址:
topk(10, http_requests_total)
(2) Gauge:可增可减的仪表盘
与Counter不同,Gauge类型的指标侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。常见指标如:node_memory_MemFree(主机当前空闲的内容大小)、node_memory_MemAvailable(可用内存大小)都是Gauge类型的监控指标。
通过Gauge指标,用户可以直接查看系统的当前状态:node_memory_MemFree对于Gauge类型的监控指标,通过PromQL内置函数delta()可以获取样本在一段时间返回内的变化情况。还可以使用deriv()计算样本的线性回归模型,甚至是直接使用predict_linear()对数据的变化趋势进行预测。
# 计算CPU温度在两个小时内的差异:
delta(cpu_temp_celsius{host="zeus"}[2h])
# 预测系统磁盘空间在4个小时之后的剩余情况:
predict_linear(node_filesystem_free{job="node"}[1h], 4 * 3600)
(3) 使用Histogram和Summary分析数据分布情况
除了Counter和Gauge类型的监控指标以外,Prometheus还定义分别定义Histogram和Summary的指标类型。Histogram和Summary主用用于统计和分析样本的分布情况。
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如CPU的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统API调用的平均响应时间为例:如果大多数API请求都维持在100ms的响应时间范围内,而个别请求的响应时间需要5s,那么就会导致某些WEB页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。例如,统计延迟在0~10ms之间的请求数有多少而10~20ms之间的请求数又有多少,通过这种方式可以快速分析系统慢的原因。Histogram和Summary都是为了能够解决这样问题的存在,通过Histogram和Summary类型的监控指标,我们可以快速了解监控样本的分布情况。
# HELP prometheus_tsdb_wal_fsync_duration_seconds Duration of WAL fsync.
# TYPE prometheus_tsdb_wal_fsync_duration_seconds summary
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
从上面的样本中可以得知当前Prometheus Server进行wal_fsync操作的总次数为216次,耗时2.888716127000002s。其中中位数(quantile=0.5)的耗时为0.012352463,9分位数(quantile=0.9)的耗时为0.014458005s。
3.4 PromQL基础
Prometheus通过指标名称(metrics name)以及对应的一组标签(labelset)唯一定义一条时间序列。指标名称反映了监控样本的基本标识,而label则在这个基本特征上为采集到的数据提供了多种特征维度。用户可以基于这些特征维度过滤,聚合,统计从而产生新的计算后的一条时间序列。
PromQL是Prometheus内置的数据查询语言,其提供对时间序列数据丰富的查询,聚合以及逻辑运算能力的支持。并且被广泛应用在Prometheus的日常应用当中,包括对数据查询、可视化、告警处理当中。可以这么说,PromQL是Prometheus所有应用场景的基础,理解和掌握PromQL是Prometheus入门的第一课。
(1) 查询时间序列
当Prometheus通过Exporter采集到相应的监控指标样本数据后,我们就可以通过PromQL对监控样本数据进行查询。
当我们直接使用监控指标名称查询时,可以查询该指标下的所有时间序列。如:
prometheus_http_requests_total
# 等价于
prometheus_http_requests_total{}
PromQL还支持用户根据时间序列的标签匹配模式来对时间序列进行过滤,目前主要支持两种匹配模式:完全匹配(=)和排除匹配(!=)。
通过使用label=value可以选择那些标签满足表达式定义的时间序列; 反之使用label!=value则可以根据标签匹配排除时间序列;
# 查询所有prometheus_http_requests_total时间序列中满足标签instance为localhost:9090的时间序列,则可以使用如下表达式:
prometheus_http_requests_total{instance="localhost:9090"}
# 反之使用instance!="localhost:9090"则可以排除这些时间序列:
prometheus_http_requests_total{instance!="localhost:9090"}
除了使用完全匹配的方式对时间序列进行过滤以外,PromQL还可以支持使用正则表达式作为匹配条件,多个表达式之间使用|进行分离:
使用label=~regx表示选择那些标签符合正则表达式定义的时间序列; 反之使用label!~regx进行排除;
# 如果想查询多个环节下的时间序列序列可以使用如下表达式:
http_requests_total{environment=~"staging|testing|development",method!="GET"}
(2) 范围查询
直接通过类似于PromQL表达式http_requests_total查询时间序列时,返回值中只会包含该时间序列中的最新的一个样本值,这样的返回结果我们称之为瞬时向量。而相应的这样的表达式称之为瞬时向量表达式。
而如果我们想过去一段时间范围内的样本数据时,我们则需要使用区间向量表达式。区间向量表达式和瞬时向量表达式之间的差异在于在区间向量表达式中我们需要定义时间选择的范围,时间范围通过时间范围选择器[]进行定义。例如,通过以下表达式可以选择最近5分钟内的所有样本数据:
http_requests_total{}[5m]
s - 秒
m - 分钟
h - 小时
d - 天
w - 周
y - 年
(3) 时间位移操作
在瞬时向量表达式或者区间向量表达式中,都是以当前时间为基准:
http_requests_total{} # 瞬时向量表达式,选择当前最新的数据
http_requests_total{}[5m] # 区间向量表达式,选择以当前时间为基准,5分钟内的数据
而如果我们想查询,5分钟前的瞬时样本数据,或昨天一天的区间内的样本数据呢? 这个时候我们就可以使用位移操作,位移操作的关键字为offset。
可以使用offset时间位移操作:
http_requests_total{} offset 5m
http_requests_total{}[1d] offset 1d
(4) 聚合操作
如果描述样本特征的标签(label)在并非唯一的情况下,通过PromQL查询数据,会返回多条满足这些特征维度的时间序列。而PromQL提供的聚合操作可以用来对这些时间序列进行处理,形成一条新的时间序列:
# 查询系统所有http请求的总量
sum(http_requests_total)
# 按照mode计算主机CPU的平均使用时间
avg(node_cpu) by (mode)
# 按照主机查询各个主机的CPU使用率
sum(sum(irate(node_cpu{mode!='idle'}[5m])) / sum(irate(node_cpu[5m]))) by (instance)
(5) 合法的PromQL
http_requests_total # 合法
http_requests_total{} # 合法
{method="get"} # 合法
{__name__=~"http_requests_total"} # 合法
{__name__=~"node_disk_bytes_read|node_disk_bytes_written"} # 合法
而如下表达式,则不合法:
{job=~".*"} # 不合法
3.5 PromQL操作符
使用PromQL除了能够方便的按照查询和过滤时间序列以外,PromQL还支持丰富的操作符,用户可以使用这些操作符对进一步的对事件序列进行二次加工。这些操作符包括:数学运算符,逻辑运算符,布尔运算符等等
(1) 数学运算符
PromQL支持的所有数学运算符如下所示:
+ (加法)
- (减法)
* (乘法)
/ (除法)
% (求余)
^ (幂运算)
例如查看内存使用率:
(node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes
(2) 逻辑运行
目前,Prometheus支持以下布尔运算符如下:
== (相等)
!= (不相等)
> (大于)
< (小于)
>= (大于等于)
<= (小于等于)
例如查看内存使用率超过0.707的数据:
(node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes > 0.707
(3) 布尔运算
布尔运算符的默认行为是对时序数据进行过滤。而在其它的情况下我们可能需要的是真正的布尔结果。例如,只需要知道当前模块的HTTP请求量是否>=1000,如果大于等于1000则返回1(true)否则返回0(false)。这时可以使用bool修饰符改变布尔运算的默认行为。
prometheus_http_requests_total > bool 5000
(4) 使用集合运算符
使用瞬时向量表达式能够获取到一个包含多个时间序列的集合,我们称为瞬时向量。 通过集合运算,可以在两个瞬时向量与瞬时向量之间进行相应的集合操作。目前,Prometheus支持以下集合运算符:
and (并且)
or (或者)
unless (排除)
vector1 and vector2 会产生
(5) 操作符优先级
在PromQL操作符中优先级由高到低依次为:
^
*, /, %
+, -
==, !=, <=, <, >=, >
and, unless
or
3.6 PromQL聚合操作
Prometheus还提供了下列内置的聚合操作符,这些操作符作用域瞬时向量。可以将瞬时表达式返回的样本数据进行聚合,形成一个新的时间序列。
rate(时间内变化率,指定时间范围内所有数据点,适合缓慢变化的计数器)
irate(时间内变化率,指定时间范围内的最近两个数据点来算速率,适合快速变化的计数器)
sum (求和)
min (最小值)
max (最大值)
avg (平均值)
stddev (标准差)
stdvar (标准差异)
count (计数)
count_values (对value进行计数)
bottomk (后n条时序)
topk (前n条时序)
quantile (分布统计)
使用聚合操作的语法如下:
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]
aggr-op: 聚合操作符
parameter: 参数(可选)
vector expression: 矢量式
without: 用于从计算结果中移除列举的标签(维度),而保留其它标签
by: 向量中只保留列出的标签(维度),其余标签则移除,必须指明标签列表
示例:
sum(prometheus_http_requests_total) without (instance)
等价于
sum(prometheus_http_requests_total) by (code,handler,job,method)
例如获取HTTP请求数前5位的时序样本数据:
topk(5, prometheus_http_requests_total)
例如找到当前样本数据中的中位数(0<v<1):
quantile(0.5, prometheus_http_requests_total)
常用top10统计promQL语句示例:
# CPU 使用率 top10
label_replace(topk(10,(100 - avg(irate(node_cpu_seconds_total{mode="idle"}[5m]))by (instance) * 100)),"ip","$1","instance","(.*):.*")
# 内存使用率 top10
label_replace(topk(10,((1 - (node_memory_MemAvailable_bytes{} / (node_memory_MemTotal_bytes{})))* 100)),"ip","$1","instance","(.*):.*")
# 磁盘使用率 top10
label_replace(topk(10,((1 - (node_memory_MemAvailable_bytes{} / (node_memory_MemTotal_bytes{})))* 100))by (instance),"ip","$1","instance","(.*):.*")
# 磁盘IO总线利用率 top10
label_replace(topk(10,(avg(irate(node_disk_io_time_seconds_total{}[1m])) by(instance)* 100)),"ip","$1","instance","(.*):.*")
# 网络下载 top10
label_replace(topk(10,(sum(irate(node_network_receive_bytes_total{device!~"tap.*|veth.*|br.*|docker.*|virbr*|lo*"}[1m])*8) by (instance))),"ip","$1","instance","(.*):.*")
# 网络上传 top10
label_replace(topk(10,(sum(irate(node_network_transmit_bytes_total{device!~"tap.*|veth.*|br.*|docker.*|virbr*|lo*"}[1m])*8) by (instance))),"ip","$1","instance","(.*):.*")
# TCP 网络包错误率 top10
label_replace(topk(10,(avg(irate(node_netstat_Tcp_InErrs{}[1m])) by (instance) / avg(irate(node_netstat_Tcp_InSegs{}[1m])) by (instance))),"ip","$1","instance","(.*):.*")
# TCP 建立连接数 top10
label_replace(topk(10,avg(node_netstat_Tcp_CurrEstab{}) by (instance)) ,"ip","$1","instance","(.*):.*")
# TCP 等待断开连接 top10
label_replace(topk(10,avg(node_sockstat_TCP_tw{}) by (instance)) ,"ip","$1","instance","(.*):.*")
# 1分钟,5分钟,15分钟CPU平均负载 top10
label_replace(topk(10,avg(node_load1{}) by (instance)),"ip","$1","instance","(.*):.*")
label_replace(topk(10,avg(node_load5{}) by (instance)),"ip","$1","instance","(.*):.*")
label_replace(topk(10,avg(node_load15{}) by (instance)),"ip","$1","instance","(.*):.*")
# CPU 上下文切换平均次数 top10
label_replace(topk(10,avg(irate(node_context_switches_total{}[5m]))by (instance)),"ip","$1","instance","(.*):.*")
# swap 交换分区使用 top10
label_replace(topk(10,avg(node_memory_SwapTotal_bytes{}-node_memory_SwapFree_bytes{}) by (instance)) ,"ip","$1","instance","(.*):.*")
3.7 PromQL子查询
常用的子查询:
avg_over_time() # 指定间隔内所有点的平均值。
min_over_time() # 指定间隔中所有点的最小值。
max_over_time() # 指定间隔内所有点的最大值。
sum_over_time() # 指定时间间隔内所有值的总和。
avg_over_time 示例:
# 查询一天空闲空间的平均值
avg_over_time(node_filesystem_files_free[1d])
min_over_time 示例:
# 一天 空闲空间的最大值
max_over_time(node_filesystem_files_free[1d])
max_over_time 示例:
# 统计prometheus上/metrics页面在5分钟内区间向量的平均值的点,在1个小时中每个点的值。
max_over_time(rate(prometheus_http_requests_total[5m])[1h:1m])
# rate(prometheus_http_requests_total[5m])[1h:1m]
# 它将五分钟的数据聚合成一个瞬时向量。
# [1h就像范围向量选择器一样,它定义了相对于查询求值时间的范围大小。
# :1m]要使用的间隔值。如果没有定义,它默认为全局计算区间。
sum_over_time 示例:
# 统计prometheus上/metrics页面在5分钟内区间向量值的点总和,在1个小时中每个点的值。
sum_over_time(rate(prometheus_http_requests_total[5m])[1h:1m])
请求数量总和:
# 最近10分钟请求数量总和
sum(max_over_time(prometheus_http_requests_total{}[10m]) - min_over_time(prometheus_http_requests_total{}[10m]))
3.8 逻辑运算(与、或、非)
and # 与
or # 或
unless # 非
and 示例:
# 同时满足多个条件
node_filesystem_size_bytes{fstype!="tmpfs"} and node_filesystem_size_bytes != 0 and node_filesystem_size_bytes{mountpoint="/root-disk"}
or 示例:
# 至少满足一个条件
node_filesystem_avail_bytes > 200000 or node_filesystem_avail_bytes < 2500000
unless 示例:
# 忽略标签为{instance="192.168.1.21:9100",job="node"}数据
up{instance="192.168.1.20:9100",job="node"} unless up{instance="192.168.1.21:9100",job="node"}
# 当标签相同时输出数据
up{instance="192.168.1.20:9100",job="node"} unless up{instance="192.168.1.20:9100",job="node"}
3.9 4个黄金指标和USE方法
监控内容对应的Exporter:
| 级别 | 监控什么 | Exporter |
|---|---|---|
| 网络 | 网络协议:http、dns、tcp、icmp;网络硬件:路由器,交换机等 | BlockBox Exporter;SNMP Exporter |
| 主机 | 资源用量 | node exporter |
| 容器 | 资源用量 | cAdvisor |
| 应用(包括Library) | 延迟,错误,QPS,内部状态等 | 代码中集成Prmometheus Client |
| 中间件状态 | 资源用量,以及服务状态 | 代码中集成Prmometheus Client |
| 编排工具 | 集群资源用量,调度等 | Kubernetes Components |
(1) 4个黄金指标
Four Golden Signals是Google针对大量分布式监控的经验总结,4个黄金指标可以在服务级别帮助衡量终端用户体验、服务中断、业务影响等层面的问题,主要关注与以下四种类型的指标:延迟,通讯量,错误以及饱和度。
- 延迟:服务请求所需时间。
记录用户所有请求所需的时间,重点是要区分成功请求的延迟时间和失败请求的延迟时间。 例如在数据库或者其他关键祸端服务异常触发HTTP 500的情况下,用户也可能会很快得到请求失败的响应内容,如果不加区分计算这些请求的延迟,可能导致计算结果与实际结果产生巨大的差异。除此以外,在微服务中通常提倡“快速失败”,开发人员需要特别注意这些延迟较大的错误,因为这些缓慢的错误会明显影响系统的性能,因此追踪这些错误的延迟也是非常重要的。
- 通讯量:监控当前系统的流量,用于衡量服务的容量需求。
流量对于不同类型的系统而言可能代表不同的含义。例如,在HTTP REST API中, 流量通常是每秒HTTP请求数;
- 错误:监控当前系统所有发生的错误请求,衡量当前系统错误发生的速率。
对于失败而言有些是显式的(比如, HTTP 500错误),而有些是隐式(比如,HTTP响应200,但实际业务流程依然是失败的)。
对于一些显式的错误如HTTP 500可以通过在负载均衡器(如Nginx)上进行捕获,而对于一些系统内部的异常,则可能需要直接从服务中添加钩子统计并进行获取。
- 饱和度:衡量当前服务的饱和度。
主要强调最能影响服务状态的受限制的资源。 例如,如果系统主要受内存影响,那就主要关注系统的内存状态,如果系统主要受限与磁盘I/O,那就主要观测磁盘I/O的状态。因为通常情况下,当这些资源达到饱和后,服务的性能会明显下降。同时还可以利用饱和度对系统做出预测,比如,“磁盘是否可能在4个小时候就满了”。
(2) RED方法
RED方法是Weave Cloud在基于Google的“4个黄金指标”的原则下结合Prometheus以及Kubernetes容器实践,细化和总结的方法论,特别适合于云原生应用以及微服务架构应用的监控和度量。主要关注以下三种关键指标:
- (请求)速率:服务每秒接收的请求数。
- (请求)错误:每秒失败的请求数。
- (请求)耗时:每个请求的耗时。
在“4大黄金信号”的原则下,RED方法可以有效的帮助用户衡量云原生以及微服务应用下的用户体验问题。
(3) USE方法
USE方法全称”Utilization Saturation and Errors Method”,主要用于分析系统性能问题,可以指导用户快速识别资源瓶颈以及错误的方法。正如USE方法的名字所表示的含义,USE方法主要关注与资源的:使用率(Utilization)、饱和度(Saturation)以及错误(Errors)。
- 使用率:关注系统资源的使用情况。 这里的资源主要包括但不限于:CPU,内存,网络,磁盘等等。100%的使用率通常是系统性能瓶颈的标志。
- 饱和度:例如CPU的平均运行排队长度,这里主要是针对资源的饱和度(注意,不同于4大黄金信号)。任何资源在某种程度上的饱和都可能导致系统性能的下降。
- 错误:错误计数。例如:“网卡在数据包传输过程中检测到的以太网网络冲突了14次”。
4 告警
告警能力在Prometheus的架构中被划分成两个独立的部分。通过在Prometheus中定义AlertRule(告警规则),Prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向Alertmanager发送告警信息。
在Prometheus中一条告警规则主要由以下几部分组成:
- 告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容。
- 告警规则:告警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警。
Alertmanager特性:
- 分组:分组机制可以将详细的告警信息合并成一个通知,避免一次性接受大量的告警通知,而无法对问题进行快速定位。
- 抑制:抑制是指当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制。
- 静默:提供了一个简单的机制可以快速根据标签对告警进行静默处理。如果接收到的告警符合静默的配置,Alertmanager则不会发送告警通知。
4.1 定义告警规则
一条典型的告警规则如下所示:
groups:
- name: example
rules:
- alert: HighErrorRate
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 10m
labels:
severity: page
annotations:
summary: High request latency
description: description info
- alert:告警规则的名称。
- expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
- for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
- labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
- annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
使用promtool工具检查告警语法:
promtool check rules /path/to/example.rules.yml
promtool工具下载地址: https://prometheus.io/docs/prometheus/latest/configuration/recording_rules/
4.2 alertmanager配置详解
Alertmanager主要负责对Prometheus产生的告警进行统一处理,因此在Alertmanager配置中一般会包含以下几个主要部分:
- 全局配置(global):用于定义一些全局的公共参数,如全局的SMTP配置,Slack配置等内容;
- 模板(templates):用于定义告警通知时的模板,如HTML模板,邮件模板等;
- 告警路由(route):根据标签匹配,确定当前告警应该如何处理;
- 接收人(receivers):接收人是一个抽象的概念,它可以是一个邮箱也可以是微信,Slack或者Webhook等,接收人一般配合告警路由使用;
- 抑制规则(inhibit_rules):合理设置抑制规则可以减少垃圾告警的产生
其完整配置格式如下:
global:
[ resolve_timeout: <duration> | default = 5m ]
[ smtp_from: <tmpl_string> ]
[ smtp_smarthost: <string> ]
[ smtp_hello: <string> | default = "localhost" ]
[ smtp_auth_username: <string> ]
[ smtp_auth_password: <secret> ]
[ smtp_auth_identity: <string> ]
[ smtp_auth_secret: <secret> ]
[ smtp_require_tls: <bool> | default = true ]
[ slack_api_url: <secret> ]
[ victorops_api_key: <secret> ]
[ victorops_api_url: <string> | default = "https://alert.victorops.com/integrations/generic/20131114/alert/" ]
[ pagerduty_url: <string> | default = "https://events.pagerduty.com/v2/enqueue" ]
[ opsgenie_api_key: <secret> ]
[ opsgenie_api_url: <string> | default = "https://api.opsgenie.com/" ]
[ hipchat_api_url: <string> | default = "https://api.hipchat.com/" ]
[ hipchat_auth_token: <secret> ]
[ wechat_api_url: <string> | default = "https://qyapi.weixin.qq.com/cgi-bin/" ]
[ wechat_api_secret: <secret> ]
[ wechat_api_corp_id: <string> ]
[ http_config: <http_config> ]
templates:
[ - <filepath> ... ]
route: <route>
receivers:
- <receiver> ...
inhibit_rules:
[ - <inhibit_rule> ... ]
在全局配置中需要注意的是resolve_timeout,该参数定义了当Alertmanager持续多长时间未接收到告警后标记告警状态为resolved(已解决)。该参数的定义可能会影响到告警恢复通知的接收时间,读者可根据自己的实际场景进行定义,其默认值为5分钟。
(1) route告警路由
alertmanager配置中的route是基于标签的告警路由,对于不同级别的告警,我们可能会有不同的处理方式,在route中可以定义更多的子Route,这些Route通过标签匹配告警的处理方式,告警的匹配有两种方式可以选择:
- 方式一:基于字符串验证,通过设置match规则判断当前告警中是否存在标签labelname并且其值等于labelvalue。
- 方式二:基于正则表达式,通过设置match_re验证当前告警标签的值是否满足正则表达式的内容。
alertmanager配置示例如下:
route:
receiver: 'default-receiver'
group_by: [cluster, alertname]
group_wait: 30s
group_interval: 10m
repeat_interval: 1h
routes:
- receiver: 'database-pager'
# 这里没有group_by,继承顶级的group_by
group_wait: 10s
match_re:
service: mysql|cassandra
- receiver: 'frontend-pager'
group_by: [product, environment]
match:
team: frontend
使用命令检查告警规则是否合法
promtool check rules /path/to/example.rules.yml
(2) receiver告警接收器发送通知
每一个receiver具有一个全局唯一的名称,并且对应一个或者多个通知方式:
name: <string>
email_configs:
[ - <email_config>, ... ]
webhook_configs:
[ - <webhook_config>, ... ]
hipchat_configs:
[ - <hipchat_config>, ... ]
pagerduty_configs:
[ - <pagerduty_config>, ... ]
pushover_configs:
[ - <pushover_config>, ... ]
slack_configs:
[ - <slack_config>, ... ]
opsgenie_configs:
[ - <opsgenie_config>, ... ]
victorops_configs:
[ - <victorops_config>, ... ]
目前官方内置的第三方通知集成包括:邮件、 即时通讯软件(如Slack、Hipchat)、移动应用消息推送(如Pushover)和自动化运维工具(例如:Pagerduty、Opsgenie、Victorops)。Alertmanager的通知方式中还可以支持Webhook,通过这种方式开发者可以实现更多个性化的扩展支持。
4.3 告警发钉钉实例
如果只是告警,不把告警消息发出去,不需要安装alertmanager和prometheus-webhook-dingtalk服务,编写告警规则,然后在prometheus配置中导入告警规则文件即可。
rule_files:
# - "first_rules.yml"
- "/etc/prometheus/rules/*.yml"
然后在浏览器访问 http://192.168.101.88:9090/alerts 可以看到有没有告警消息。
为了实现告警发钉钉消息,需要安装alertmanager和prometheus-webhook-dingtalk两个服务,下面是一个在docker上实现prometheus采集和告警发钉钉脚本。
(1) 添加告警规则配置,./rules/hoststats-alert.yml文件内容如下:
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: sum(avg without (cpu)(irate(node_cpu_seconds_total{mode!='idle'}[5m]))) by (instance) > 0.5
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} CPU usgae high"
description: "{{ $labels.instance }} CPU usage above 50% (current value: {{ $value }})"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes > 0.8
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} MEM usgae high"
description: "{{ $labels.instance }} MEM usage above 80% (current value: {{ $value }})"
(2) 添加alertmanager配置,文件./config/alertmanager.yml内容如下:
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'dingding-webhook1'
routes:
- match:
severity: critical
receiver: dingding-webhook1
- match:
severity: page
receiver: dingding-webhook2
receivers:
# 对应prometheus-webhook-dingtalk服务监听地址,改服务启动时需要添加webhook1、webhook2对应的钉钉地址参数。
- name: dingding-webhook1
webhook_configs:
- url: http://prometheus-webhook-dingtalk:8060/dingtalk/webhook1/send
- name: dingding-webhook2
webhook_configs:
- url: http://prometheus-webhook-dingtalk:8060/dingtalk/webhook2/send
(3) 修改prometheus配置,添加规则文件和报警管理器,文件./config/prometheus.yml的内容如下:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
- "/etc/prometheus/rules/*.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090','cadvisor:8080','node-exporter:9100']
修改docker-compose.yml配置,添加alertmanager和prometheus-webhook-dingtalk服务,docker-compose.yml文件内容如下:
version: "3"
services:
prometheus:
container_name: prometheus
restart: always
image: prom/prometheus:v2.11.1
ports:
- 9090:9090
command:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
volumes:
- ./config/prometheus.yml:/etc/prometheus/prometheus.yml
- ./rules:/etc/prometheus/rules
- prom-data:/prometheus
networks:
- prom-net
node-exporter:
container_name: node-exporter
restart: always
image: prom/node-exporter:latest
ports:
- 9100:9100
networks:
- prom-net
cadvisor:
container_name: cadvisor
restart: always
image: google/cadvisor:latest
ports:
- 9101:8080
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
networks:
- prom-net
grafana:
container_name: grafana
image: grafana/grafana:6.2.5
restart: always
ports:
- "3003:3000"
volumes:
- ./grafana/datasource.yaml:/etc/grafana/provisioning/datasources/datasource.yaml
- grafana-data:/var/lib/grafana
networks:
- prom-net
#environment:
# - GF_SECURITY_ADMIN_PASSWORD=123456
# prometheus的告警信息发送到alertmanager服务,alertmanager可以转发告警信息到邮件、微信、钉钉等
alertmanager:
container_name: alertmanager
restart: always
image: prom/alertmanager:latest
command:
- "--config.file=/etc/alertmanager/alertmanager.yml"
- "--storage.path=/alertmanager"
volumes:
- ./config/alertmanager.yml:/etc/alertmanager/alertmanager.yml
- alertmanager-data:/alertmanager
ports:
- 9093:9093
networks:
- prom-net
# 发送告警信息到钉钉
prometheus-webhook-dingtalk:
container_name: prometheus-webhook-dingtalk
restart: always
image: timonwong/prometheus-webhook-dingtalk:latest
command:
- "--ding.profile=webhook1=https://oapi.dingtalk.com/robot/send?access_token=f6ac4c35e3aedd9a3d34b9d6950d8e0d0891c4d6837b1596a738e3b9d77e932b"
- "--ding.profile=webhook2=https://oapi.dingtalk.com/robot/send?access_token=fcc0038d1d09712449a1ba129e0e11748e1bc63f547d49140db35079e29c3973"
ports:
- 8060:8060
networks:
- prom-net
volumes:
prom-data:
driver: local
grafana-data:
driver: local
alertmanager-data:
driver: local
networks:
prom-net:
driver: bridge
启动服务:
docker-compose up -d
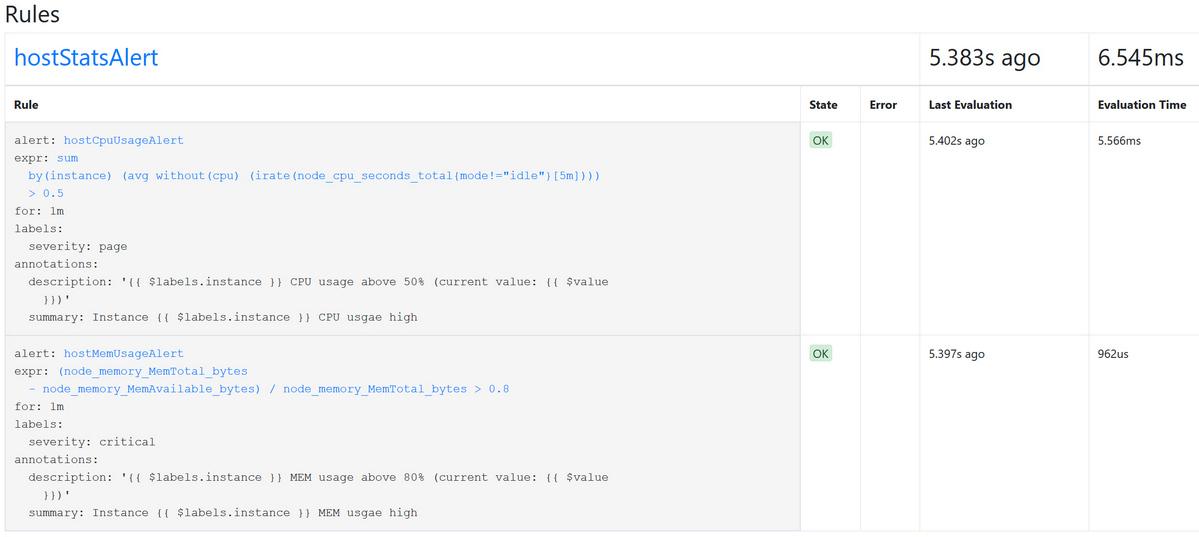
在浏览器打开 http://192.168.101.88:9090/rules ,查看告警文件是否生效,如下图所示:
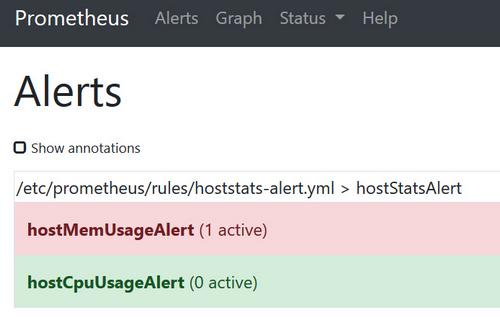
点击菜单Alerts,查看是否有告警触发,未触发时背景是绿色 0 active,触发后有两种状态pending和firing,pending状态的背景为黄色 1 active,firing状态背景变为红色 1 active,如下图所示:
测试让其触发告警:
# 启动测试容器
docker run --rm -it busybox sh
# 执行耗cpu命令
cat /dev/zero>/dev/null
# 注意:如果一个容器不够,可以启动多几个
# 因为rules文件里设置for为1分钟,说明如果1分钟后告警条件持续满足,则会实际触发告警并且告警状态为FIRING。
对于已经pending或者firing的告警,prometheus也会将它们存储到时间序列ALERTS{}中,可以通过表达式,查询告警结果如下:
ALERTS{alertname="hostMemUsageAlert",alertstate="firing",instance="node-exporter:9100",job="prometheus",severity="critical"}
样本值为1表示当前告警处于活动状态(pending或者firing),当告警从活动状态转换为非活动状态时,样本值则为0。
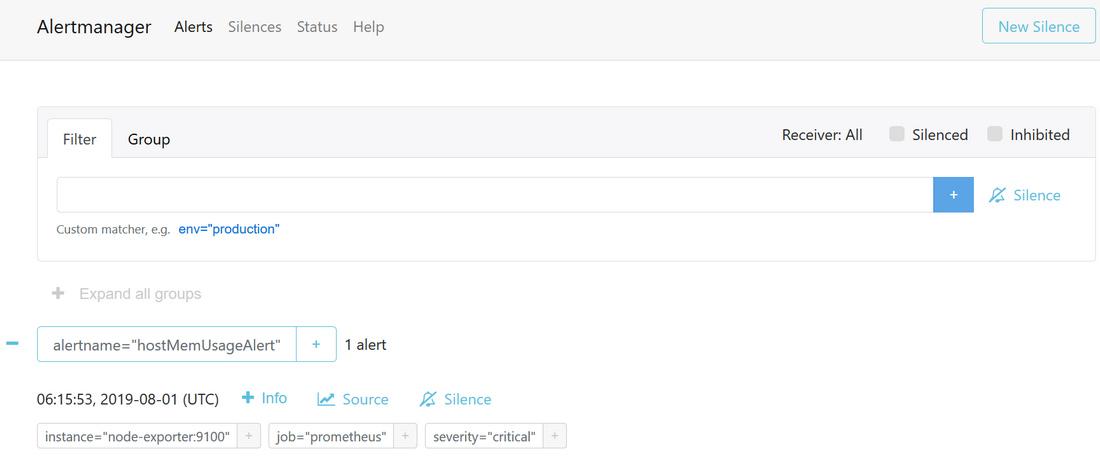
在浏览器访问alertmanager服务界面( http://192.168.101.88:9093/#/alerts ),如果prometheus触发(firing)了告警,会显示告警消息记录,同时也会把告警消息转发给prometheus-webhook-dingtalk服务,如下图所示:
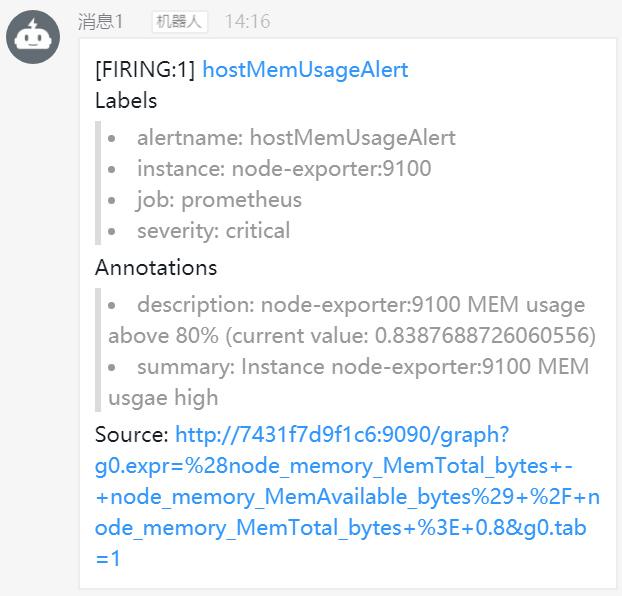
当触发告警时,alertmanager服务通过http推送(POST)告警信息给prometheus-webhook-dingtalk服务,推送告警消息的url格式为 http://xxxxx:8060/dingtalk/webhook1/send ,其中webhook1是钉钉地址对应的名称,该名称在prometheus-webhook-dingtalk服务启动时设置,docker-compose.yml中prometheus-webhook-dingtalk服务启动参数如下:
command:
- "--ding.profile=webhook1=https://oapi.dingtalk.com/robot/send?access_token=xxxxxx"
prometheus-webhook-dingtalk服务接收到消息后从url解析出钉钉地址对应的名称,根据名称获得钉钉地址,然后把告警消息推送到钉钉,如下图所示:
5 exporter
广义上讲所有可以向Prometheus提供监控样本数据的程序都可以被称为一个Exporter。而Exporter的一个实例称为target。
(1) 常用Exporter
| 范围 | 常用Exporter |
|---|---|
| 数据库 | MySQL Exporter, Redis Exporter, MongoDB Exporter, MSSQL Exporter等 |
| 硬件 | Apcupsd Exporter,IoT Edison Exporter, IPMI Exporter, Node Exporter等 |
| 消息队列 | Beanstalkd Exporter, Kafka Exporter, NSQ Exporter, RabbitMQ Exporter等 |
| 存储 | Ceph Exporter, Gluster Exporter, HDFS Exporter, ScaleIO Exporter等 |
| HTTP服务 | Apache Exporter, HAProxy Exporter, Nginx Exporter等 |
| API服务 | AWS ECS Exporter, Docker Cloud Exporter, Docker Hub Exporter, GitHub Exporter等 |
| 日志 | Fluentd Exporter, Grok Exporter等 |
| 监控系统 | Collectd Exporter, Graphite Exporter, InfluxDB Exporter, Nagios Exporter, SNMP Exporter等 |
| 其它 | Blockbox Exporter, JIRA Exporter, Jenkins Exporter, Confluence Exporter等 |
(2) Exporter的运行方式
从Exporter的运行方式上来讲,又可以分为:
- 独立使用的
以已经使用过的Node Exporter为例,由于操作系统本身并不直接支持Prometheus,同时用户也无法通过直接从操作系统层面上提供对Prometheus的支持。因此,用户只能通过独立运行一个程序的方式,通过操作系统提供的相关接口,将系统的运行状态数据转换为可供Prometheus读取的监控数据。 除了Node Exporter以外,比如MySQL Exporter、Redis Exporter等都是通过这种方式实现的。 这些Exporter程序扮演了一个中间代理人的角色。
- 集成到应用中的
为了能够更好的监控系统的内部运行状态,有些开源项目如Kubernetes,ETCD等直接在代码中使用了Prometheus的Client Library,提供了对Prometheus的直接支持。这种方式打破的监控的界限,让应用程序可以直接将内部的运行状态暴露给Prometheus,适合于一些需要更多自定义监控指标需求的项目。
(3) Exporter规范
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 3.0703125
如果当前行以# HELP开始,Prometheus将会按照以下规则对内容进行解析,得到当前的指标名称以及相应的说明信息。
如果当前行以# TYPE开始,Prometheus会按照以下规则对内容进行解析,得到当前的指标名称以及指标类型,如果没有明确的指标类型需要返回为untyped。
除了# 开头的所有行都会被视为是监控样本数据。
5.1 linux系统监控
(1) 启动node-exporter
使用docker启动,docker-compose.yml内容如下:
version: '3.1'
services:
node-exporter:
image: prom/node-exporter:v1.2.2
container_name: node-exporter
command:
- '--path.rootfs=/host'
network_mode: host
pid: host
restart: always
volumes:
- '/:/host:ro,rslave'
(2) 配置prometheus
在Prometheus配置文件添加job,内容如下:
- job_name: 'node-exporter'
scrape_interval: 15s
static_configs:
- targets: ['192.168.111.128:9100']
labels:
project: "电商"
env: "dev"
重载prometheus配置,使配置生效
curl -X POST http://192.168.111.128:9090/-/reload
注:启动prometheus时必须添加参数–web.enable-lifecycle,表示开启prometheus重载配置功能。
(3) 导入grafana模板
打开grafana,点击import,输入编号12377,其中数字编号是官网 https://grafana.com/grafana/dashboards 的一个模板编号,确定之后,grafana会自动从grafana官网下载模板json文件。
5.2 cadvisor容器监控
cadvisor是Google开源的一款用于展示和分析容器运行状态的可视化工具。通过在主机上运行CAdvisor用户可以轻松的获取到当前主机上容器的运行统计信息,并以图表的形式向用户展示。
(1) 启动cadvisor容器
使用docker启动,docker-compose.yml内容如下:
version: '3.1'
services:
cadvisor-exporter:
image: gcr.io/cadvisor/cadvisor:v0.37.5
container_name: cadvisor
# 设置容器权限为root
privileged: true
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
ports:
- 9192:8080
restart: always
注:如果启动容器cadvisor时出现下面错误:
Failed to start container manager: inotify_add_watch /sys/fs/cgroup/cpuacct,cpu: no such file or directory
解决办法:在管理员模式下执行
mount -o remount,rw '/sys/fs/cgroup'
ln -s /sys/fs/cgroup/cpu,cpuacct /sys/fs/cgroup/cpuacct,cpu
(2) 配置Prometheus
在prometheus的配置文件scrape_configs下添加配置:
- job_name: 'cadvisor'
scrape_interval: 60s
static_configs:
- targets: ['192.168.11.128:9192']
重载prometheus配置,使配置生效
curl -X POST http://192.168.111.128:9090/-/reload
注:启动prometheus时必须添加参数–web.enable-lifecycle,表示开启prometheus重载配置功能。
(3) 导入grafana模板
打开grafana,点击import,输入编号14282,其中数字编号是官网 https://grafana.com/grafana/dashboards 的模板编号,确定之后,grafana会自动从grafana官网下载模板json文件。
使用14282模板时,需要做一下调整,可以结合node-exporter在一个界面展示。
# 修改变量host的Query字段值
label_values(cadvisor_version_info{}, instance)
# 根据实际情况是否过滤显示端口,字段Regex值
/([^:]+):.*/
# 如果过滤端口,每个dashboard都需要添加
instance=~"$host:.*"
(4) 一些常使用的监控
下面表格中列举了一些cadvisor中获取到的典型监控指标:
| 指标名称 | 类型 | 含义 |
|---|---|---|
| container_cpu_load_average_10s | gauge | 过去10秒容器CPU的平均负载 |
| container_cpu_usage_seconds_total | counter | 容器在每个CPU内核上的累积占用时间 (单位:秒) |
| container_cpu_system_seconds_total | counter | System CPU累积占用时间(单位:秒) |
| container_cpu_user_seconds_total | counter | User CPU累积占用时间(单位:秒) |
| container_fs_usage_bytes | gauge | 容器中文件系统的使用量(单位:字节) |
| container_fs_limit_bytes | gauge | 容器可以使用的文件系统总量(单位:字节) |
| container_fs_reads_bytes_total | counter | 容器累积读取数据的总量(单位:字节) |
| container_fs_writes_bytes_total | counter | 容器累积写入数据的总量(单位:字节) |
| container_memory_max_usage_bytes | gauge | 容器的最大内存使用量(单位:字节) |
| container_memory_usage_bytes | gauge | 容器当前的内存使用量(单位:字节 |
| container_spec_memory_limit_bytes | gauge | 容器的内存使用量限制 |
| machine_memory_bytes | gauge | 当前主机的内存总量 |
| container_network_receive_bytes_total | counter | 容器网络累积接收数据总量(单位:字节) |
| container_network_transmit_bytes_total | counter | 容器网络累积传输数据总量(单位:字节) |
获取监控值的表达式:
# 计算容器的CPU使用率
sum(irate(container_cpu_usage_seconds_total{image!=""}[1m])) without (cpu)
# 查询容器内存使用量(字节)
container_memory_usage_bytes{image!=""}
# 查询容器网络接收量速率(字节/秒)
sum(rate(container_network_receive_bytes_total{image!=""}[1m])) without (interface)
# 查询容器网络传输量速率(字节/秒)
sum(rate(container_network_transmit_bytes_total{image!=""}[1m])) without (interface)
# 查询容器文件系统读取速率(字节/秒)
sum(rate(container_fs_reads_bytes_total{image!=""}[1m])) without (device)
# 查询容器文件系统写入速率(字节/秒)
sum(rate(container_fs_writes_bytes_total{image!=""}[1m])) without (device)
5.3 mysql监控
通过mysql exporter实现对mysql数据库的性能以及资源利用率进行监控和度量。
(1) 启动mysql-exporter容器
使用docker启动,docker-compose.yml内容如下:
version: '3.1'
services:
mysql-exporter:
image: prom/mysqld-exporter:v0.13.0
restart: always
ports:
- 9104:9104
environment:
DATA_SOURCE_NAME: "root:123456@(192.168.111.128:3306)/"
(2) 配置Prometheus
在prometheus的配置文件scrape_configs下添加配置:
# mysql资源export
- job_name: 'mysql-exporter'
static_configs:
- targets: ['192.168.111.128:9104']
#labels:
#project: 'dbaas'
#environment: 'dev'
重载prometheus配置,使配置生效
curl -X POST http://192.168.111.128:9090/-/reload
注:启动prometheus时必须添加参数–web.enable-lifecycle,表示开启prometheus重载配置功能。
可以在prometheus UI中查看到当前所有的Target状态,如果为up状态,说明mysql-exporter与prometheus集成成功。
(3) 导入grafana
把dashboard id(单机版536或集群版537)导入到grafana的dashboard。
(4) 一些mysql常使用的监控指标
- 监控数据库吞吐量
对于数据库而言,最重要的工作就是实现对数据的增、删、改、查。为了衡量数据库服务器当前的吞吐量变化情况。在mysql内部通过一个名为Questions的计数器,当客户端发送一个查询语句后,其值就会加1,对应mysql语句:
SHOW GLOBAL STATUS LIKE “Questions”;
一般还可以从监控读操作和写操作的执行情况进行判断。通过mysql全局状态中的Com_select可以查询到当前服务器执行查询语句的总次数:相应的,也可以通过Com_insert、Com_update以及Com_delete的总量衡量当前服务器写操作的总次数,通过以下指令查询当前mysql实例insert语句的执行次数总量:
SHOW GLOBAL STATUS LIKE “Com_insert”;
通过以上监控指标,以及实际监控的场景,我们可以利用PromQL快速建立多个监控项。
# 查看当前mysql实例查询速率的变化情况,查询数量的突变往往暗示着可能发生了某些严重的问题,因此用于用户应该关注并且设置响应的告警规则,以及时获取该指标的变化情况
rate(mysql_global_status_questions[2m])
# 查看当前MySQL实例写操作速率的变化情况
sum(rate(mysql_global_status_commands_total{command=~"insert|update|delete"}[2m])) without (command)
- 监控连接情况
在MySQL中通过全局设置max_connections限制了当前服务器允许的最大客户端连接数量。一旦可用连接数被用尽,新的客户端连接都会被直接拒绝。用户可以通过以下指令查看当前MySQL服务的max_connections配置:
SHOW VARIABLES LIKE ‘max_connections’;
mysql_global_variables_max_connections: 允许的最大连接数;
mysql_global_status_threads_connected: 当前打开的连接;
mysql_global_status_threads_running:当前正在使用的连接数;
mysql_global_status_aborted_connects:当前拒绝的连接数;
mysql_global_status_connection_errors_total{error=“max_connections”}:由于超出最大连接数导致的错误;
mysql_global_status_connection_errors_total{error=“internal”}:由于系统内部导致的错误;
通过以上监控指标,以及实际监控的场景,我们可以利用PromQL快速建立多个监控项。
# 查询当前剩余的可用连接数
mysql_global_variables_max_connections - mysql_global_status_threads_connected
# 查询当前MySQL实例连接拒绝数
mysql_global_status_aborted_connects
- 监控缓冲池使用情况
mysql默认的存储引擎InnoDB使用了一片称为缓冲池的内存区域,用于缓存数据表以及索引的数据。 当缓冲池的资源使用超出限制后,可能会导致数据库性能的下降,同时很多查询命令会直接在磁盘中执行,导致磁盘I/O不断攀升。
在mysql查看当前缓冲池中的内存页的总页数:
SHOW GLOBAL STATUS LIKE “Innodb_buffer_pool_pages_total”;
在mysql查看正常从缓冲池读取数据的请求数量:
SHOW GLOBAL STATUS LIKE “Innodb_buffer_pool_read_requests”;
当缓冲池无法满足时,mysql只能从磁盘中读取数据,如果Innodb_buffer_pool_reads的值开始增加,可能意味着数据库的性能有问题,查看从磁盘读取数据的请求数量:
SHOW GLOBAL STATUS LIKE “Innodb_buffer_pool_reads”;
通过以上监控指标,以及实际监控的场景,我们可以利用PromQL快速建立多个监控项。
# 通过以下PromQL可以得到各个MySQL实例的缓冲池利用率:
(sum(mysql_global_status_buffer_pool_pages) by (instance) - sum(mysql_global_status_buffer_pool_pages{state="free"}) by (instance)) / sum(mysql_global_status_buffer_pool_pages) by (instance)
# 计算2分钟内磁盘读取请求次数的增长率的变化情况:
rate(mysql_global_status_innodb_buffer_pool_reads[2m])
- 查询性能
MySQL还提供了一个Slow_queries的计数器,当查询的执行时间超过long_query_time的值后,计数器就会+1,其默认值为10秒。
在mysql查看慢查询命令:
SHOW VARIABLES LIKE ‘long_query_time’;
在mysql查看慢查询的数量:
SHOW GLOBAL STATUS LIKE “Slow_queries”;
通过监控Slow_queries的增长率,可以反映出当前MySQL服务器的性能状态:
rate(mysql_global_status_slow_queries[2m])
5.4 redis监控
(1) 启动redis-exporter
使用docker启动,docker-compose.yml内容如下:
version: '3.1'
services:
redis-exporter:
container_name: redis-exporter
image: bitnami/redis-exporter:1.27.1
restart: always
ports:
- 9121:9121
command:
- "-redis.addr=redis://192.168.83.133:6379"
- "-redis.password=123456"
(2) 配置prometheus
在Prometheus配置文件添加job,内容如下:
- job_name: 'redis-exporter'
scrape_interval: 15s
static_configs:
- targets: ['192.168.111.128:9121']
重载prometheus配置,使配置生效
curl -X POST http://192.168.111.128:9090/-/reload
注:启动prometheus时必须添加参数–web.enable-lifecycle,表示开启prometheus重载配置功能。
(3) 导入grafana模板
打开grafana,点击import,输入编号763,其中数字编号是官网 https://grafana.com/grafana/dashboards 的一个模板编号,确定之后,grafana会自动从grafana官网下载模板json文件。
5.5 blackbox exporter网络探测
白盒监控包括主机的资源用量、容器的运行状态、数据库中间件的运行数据,通过白盒能够了解其内部的实际运行状态,通过对监控指标的观察能够预判可能出现的问题,从而对潜在的不确定因素进行优化。
黑盒监控相较于白盒监控最大的不同在于黑盒监控是以故障为导向当故障发生时,黑盒监控能快速发现故障,而白盒监控则侧重于主动发现或者预测潜在的问题。一个完善的监控目标是要能够从白盒的角度发现潜在问题,能够在黑盒的角度快速发现已经发生的问题。
(1) 启动blackbox-exporter容器
使用docker启动,docker-compose.yml内容如下:
version: '3.1'
services:
blackbox-exporter:
container_name: blackbox-exporter
restart: always
image: prom/blackbox-exporter:v0.19.0
command:
- "--config.file=/config/blackbox.yml"
volumes:
- $PWD/config/blackbox.yml:/config/blackbox.yml
ports:
- 9115:9115
配置文件blackbox.yml内容如下:
modules:
http_2xx:
prober: http
timeout: 5s
http:
method: GET
tcp_connect:
prober: tcp
timeout: 5s
(2) 配置prometheus
在prometheus的配置文件scrape_configs下添加配置:
# http export
- job_name: 'blackbox'
scrape_interval: 30s #每次获取数据的时间间隔
metrics_path: /probe
params:
module: [http_2xx] # Look for a HTTP 200 response.
static_configs:
- targets:
# 监控目标
- https://www.baidu.com
- https://zhuyasen.com
- https://test.demo.com
- http://example:8080
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: blackbox-exporter:9115 # The blackbox exporter's real hostname:port.
重载prometheus配置,使配置生效
curl -X POST http://192.168.111.128:9090/-/reload
注:启动prometheus时必须添加参数–web.enable-lifecycle,表示开启prometheus重载配置功能。
(3) 导入grafana模板
打开grafana,点击import,输入编号13659或9965,其中数字编号是官网 https://grafana.com/grafana/dashboards 的一个模板编号,确定之后,grafana会自动从grafana官网下载模板json文件。
5.6 linux进程监控
(1) 启动process-exporter
使用docker启动,docker-compose.yml内容如下:
version: '3.1'
services:
process-exporter:
image: ncabatoff/process-exporter:0.7.5
volumes:
- /proc:/host/proc
- $PWD/config/process.yml:/config/process.yml
command:
- '--procfs=/host/proc'
- '--config.path=/config/process.yml'
ports:
- 9256:9256
restart: always
GitHub地址:https://github.com/ncabatoff/process-exporter
配置文件process.yml如下:
process_names:
- comm:
- chromium-browse
- bash
- prometheus
- gvim
- exe:
- /sbin/upstart
cmdline:
- --user
name: upstart:-user
(2) 配置prometheus
在Prometheus配置文件添加job,内容如下:
- job_name: 'process-exporter'
scrape_interval: 15s
static_configs:
- targets: ['192.168.83.133:9256']
(3) 导入grafana模板
打开grafana,点击import,输入编号249,其中数字编号是官网 https://grafana.com/grafana/dashboards 的一个模板编号,确定之后,grafana会自动从grafana官网下载模板json文件。
6 kubernetes监控
6.1 使用Prometheus监控Kubernetes集群
监控Kubernetes集群监控的各个维度以及策略:
| 目标 | 服务发现模式 | 监控方法 | 数据源 |
|---|---|---|---|
| 从集群各节点kubelet组件中获取节点kubelet的基本运行状态的监控指标 | node | 白盒监控 | kubelet |
| 从集群各节点kubelet内置的cAdvisor中获取,节点中运行的容器的监控指标 | node | 白盒监控 | kubelet |
| 从部署到各个节点的Node Exporter中采集主机资源相关的运行资源 | node | 白盒监控 | node exporter |
| 对于内置了Promthues支持的应用,需要从Pod实例中采集其自定义监控指标 | pod | 白盒监控 | custom pod |
| 获取API Server组件的访问地址,并从中获取Kubernetes集群相关的运行监控指标 | endpoints | 白盒监控 | api server |
| 获取集群中Service的访问地址,并通过Blackbox Exporter获取网络探测指标 | service | 黑盒监控 | blackbox exporter |
| 获取集群中Ingress的访问信息,并通过Blackbox Exporter获取网络探测指标 | ingress | 黑盒监控 | blackbox exporter |
(1) 从Kubelet获取节点运行状态
修改prometheus.yml配置文件,并添加以下采集任务配置:
- job_name: 'kubernetes-kubelet'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
通过指标kubelet_pod_start_latency_microseconds可以获得当前节点中Pod启动时间相关的统计数据:
kubelet_pod_start_latency_microseconds{quantile=“0.99”}/1000000
监控指标kubeletdocker*还可以体现出kubelet与当前节点的docker服务的调用情况,从而可以反映出docker本身是否会影响kubelet的性能表现等问题:
kubelet_pod_start_latency_microseconds_sum / kubelet_pod_start_latency_microseconds_count
(2) 使用NodeExporter监控集群资源使用情况
修改prometheus.yml配置文件,并添加以下采集任务配置:
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
(3) 从kube-apiserver获取集群运行监控指标
修改prometheus.yml配置文件,并添加以下采集任务配置:
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- target_label: __address__
replacement: kubernetes.default.svc:443
(4) 对Ingress和Service进行网络探测
修改prometheus.yml配置文件,并添加以下采集任务配置:
- job_name: 'kubernetes-services'
scrape_interval: 20s #每次获取数据的时间间隔
kubernetes_sd_configs:
- role: service
metrics_path: /probe
params:
module: [http_2xx]
relabel_configs:
# 过滤探测目标service
# 如果注释掉下面source_labels三行,会探测所有service
# 如果不注释,只有service的metadata里添加注解(annotations) prometheus.io/probe: "true"才会被探测
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__address__]
target_label: __param_target
- target_label: __address__
replacement: blackbox-exporter:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
target_label: kubernetes_name
- job_name: 'kubernetes-ingresses'
scrape_interval: 20s #每次获取数据的时间间隔
kubernetes_sd_configs:
- role: ingress
metrics_path: /probe
params:
module: [http_2xx]
relabel_configs:
# 过滤探测目标ingresses
# 如果注释掉下面source_labels三行,会探测所有ingresses
# 如果不注释,只有ingresses的metadata里添加注解(annotations) prometheus.io/probe: "true"才会被探测
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__meta_kubernetes_ingress_scheme,__address__,__meta_kubernetes_ingress_path]
regex: (.+);(.+);(.+)
replacement: ${1}://${2}${3}
target_label: __param_target
- target_label: __address__
replacement: blackbox-exporter:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_ingress_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_ingress_name]
target_label: kubernetes_name
启动blackbox服务,启动脚本如下:
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app: blackbox-exporter
name: blackbox-exporter
namespace: monitoring
data:
blackbox.yml: |-
modules:
http_2xx:
prober: http
timeout: 30s
http:
valid_http_versions: ["HTTP/1.1", "HTTP/2"]
valid_status_codes: [200,302,301,401,404]
method: GET
preferred_ip_protocol: "ip4"
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: blackbox-exporter
namespace: monitoring
spec:
selector:
matchLabels:
app: blackbox-exporter
replicas: 1
template:
metadata:
labels:
app: blackbox-exporter
spec:
restartPolicy: Always
containers:
- name: blackbox-exporter
image: prom/blackbox-exporter:v0.14.0
imagePullPolicy: IfNotPresent
ports:
- name: blackbox-port
containerPort: 9115
readinessProbe:
tcpSocket:
port: 9115
initialDelaySeconds: 20
timeoutSeconds: 5
resources:
requests:
memory: 10Mi
cpu: 10m
limits:
memory: 60Mi
cpu: 200m
volumeMounts:
- name: config
mountPath: /etc/blackbox_exporter
args:
- --config.file=/etc/blackbox_exporter/blackbox.yml
- --log.level=debug
- --web.listen-address=:9115
volumes:
- name: config
configMap:
name: blackbox-exporter
---
apiVersion: v1
kind: Service
metadata:
labels:
app: blackbox-exporter
name: blackbox-exporter
namespace: monitoring
annotations:
prometheus.io/scrape: 'true'
spec:
selector:
app: blackbox-exporter
ports:
- name: blackbox
port: 9115
targetPort: 9115
protocol: TCP
遇到问题:
在kubernetes-apiservers的target出现错误提示信息:
Get https://192.168.99.100:10250/metrics: x509: cannot validate certificate for 192.168.99.100 because it doesn’t contain any IP SANs
这是由于当前使用的ca证书中,并不包含192.168.99.100的地址信息。
解决方法:
第一种方法是直接跳过ca证书校验过程,通过在tls_config中设置 insecure_skip_verify为true即可。 这样Promthues在采集样本数据时,将会自动跳过ca证书的校验过程。
第二种方式,不直接通过kubelet的metrics服务采集监控数据,而通过Kubernetes的api-server提供的代理API访问各个节点中kubelet的metrics服务:
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
6.2 认识Prometheus Operator
为了在Kubernetes能够方便的管理和部署Prometheus,使用ConfigMap来管理Prometheus配置文件。每次对Prometheus配置文件进行升级时,我们需要手动移除已经运行的Pod实例,从而让Kubernetes可以使用最新的配置文件创建Prometheus,这种通过手动的方式部署和升级Prometheus过程繁琐并且效率低下。
(1) Prometheus Operator的工作原理
从概念上来讲Operator就是针对管理特定应用程序的,在Kubernetes基本的Resource和Controller的概念上,以扩展Kubernetes api的形式。帮助用户创建,配置和管理复杂的有状态应用程序。从而实现特定应用程序的常见操作以及运维自动化。
Prometheus的本职就是一组用户自定义的CRD资源以及Controller的实现,Prometheus Operator负责监听这些自定义资源的变化,并且根据这些资源的定义自动化的完成如Prometheus Server自身以及配置的自动化管理工作。
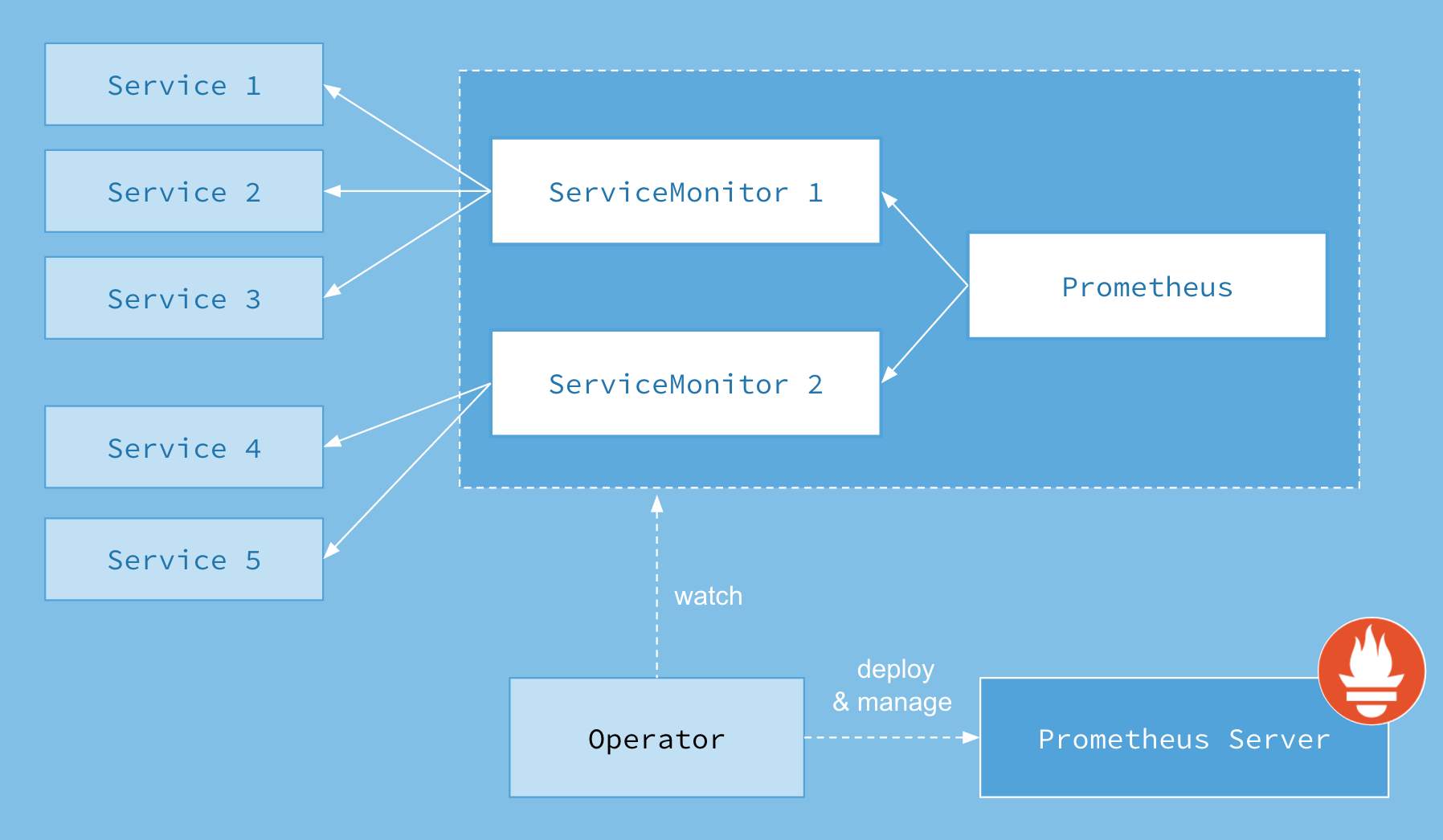
(2) Prometheus Operator能做什么
Prometheus Operator能够帮助用户自动化的创建以及管理Prometheus Server以及其相应的配置,目前提供的️4类资源:
- Prometheus:声明式创建和管理Prometheus Server实例;
- ServiceMonitor:负责声明式的管理监控配置;
- PrometheusRule:负责声明式的管理告警配置;
- Alertmanager:声明式的创建和管理Alertmanager实例。
(3) 安装Prometheus Operator
部署prometheus-operator.yml脚本文件内容如下:
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.31.1
name: prometheus-operator
namespace: monitoring
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.31.1
name: prometheus-operator
rules:
- apiGroups:
- apiextensions.k8s.io
resources:
- customresourcedefinitions
verbs:
- '*'
- apiGroups:
- monitoring.coreos.com
resources:
- alertmanagers
- prometheuses
- prometheuses/finalizers
- alertmanagers/finalizers
- servicemonitors
- podmonitors
- prometheusrules
verbs:
- '*'
- apiGroups:
- apps
resources:
- statefulsets
verbs:
- '*'
- apiGroups:
- ""
resources:
- configmaps
- secrets
verbs:
- '*'
- apiGroups:
- ""
resources:
- pods
verbs:
- list
- delete
- apiGroups:
- ""
resources:
- services
- services/finalizers
- endpoints
verbs:
- get
- create
- update
- delete
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- namespaces
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.31.1
name: prometheus-operator
namespace: monitoring
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus-operator
subjects:
- kind: ServiceAccount
name: prometheus-operator
namespace: monitoring
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.31.1
name: prometheus-operator
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
template:
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.31.1
spec:
containers:
- args:
- --kubelet-service=kube-system/kubelet
- --logtostderr=true
- --config-reloader-image=quay.io/coreos/configmap-reload:v0.0.1
- --prometheus-config-reloader=quay.io/coreos/prometheus-config-reloader:v0.31.1
#image: quay.io/coreos/prometheus-operator:v0.31.1
image: 281073576117.dkr.ecr.cn-north-1.amazonaws.com.cn/prometheus-operator:v0.31.1
name: prometheus-operator
ports:
- containerPort: 8080
name: http
resources:
limits:
cpu: 200m
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
securityContext:
allowPrivilegeEscalation: false
nodeSelector:
beta.kubernetes.io/os: linux
securityContext:
runAsNonRoot: true
runAsUser: 65534
serviceAccountName: prometheus-operator
---
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.31.1
name: prometheus-operator
namespace: monitoring
spec:
clusterIP: None
ports:
- name: http
port: 8080
targetPort: http
selector:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
启动prometheus operator:
kubectl apply -f prometheus-operator.yml
查看启动情况:
kubectl get all -n monitoring
查看新添加的自定义资源:
kubectl get crd
NAME CREATED AT
alertmanagers.monitoring.coreos.com 2019-08-14T05:56:46Z
podmonitors.monitoring.coreos.com 2019-08-14T05:56:50Z
prometheuses.monitoring.coreos.com 2019-08-14T05:56:46Z
prometheusrules.monitoring.coreos.com 2019-08-14T05:56:50Z
servicemonitors.monitoring.coreos.com 2019-08-14T05:56:50Z
6.3 使用Operator管理Prometheus
(1) 创建Prometheus实例
当集群中已经安装Prometheus Operator之后,对于部署Prometheus Server实例就变成了声明一个Prometheus资源,安装Prometheus的部署脚本prometheus-inst.yml文件内容如下:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: inst
namespace: monitoring
spec:
resources:
requests:
memory: 400Mi
启动prometheus:
kubectl apply -f prometheus-inst.yml
查看sts和pod实例启动情况:
kubectl get sts,pod -n monitoring
通过port-forward访问Prometheus实例:
kubectl port-forward –address=0.0.0.0 statefulsets/prometheus-inst 9090:9090 -n monitoring
如果能在浏览器访问 http://
(2) 使用ServiceMonitor管理监控配置
修改监控配置项是Prometheus下常用的运维操作之一,为了能够自动化的管理Prometheus的配置,Prometheus Operator使用了自定义资源类型ServiceMonitor来描述监控对象的信息。
部署一个示例应用,部署脚本example-app.yaml内容如下:
kind: Service
apiVersion: v1
metadata:
name: example-app
labels:
app: example-app
spec:
selector:
app: example-app
ports:
- name: web
port: 8080
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: example-app
spec:
replicas: 3
template:
metadata:
labels:
app: example-app
spec:
containers:
- name: example-app
image: fabxc/instrumented_app
ports:
- name: web
containerPort: 8080
查看实例启动情况:
kubectl get svc,pod | grep example-app
通过port-forward访问任意Pod实例:
kubectl port-forward –address=0.0.0.0 deployments/example-app 8080:8080
在浏览器查看 http://
为了能够让Prometheus能够采集应用的监控数据,在原生的Prometheus配置方式中,我们在Prometheus配置文件中定义单独的Job,同时使用kubernetes_sd定义整个服务发现过程。而在Prometheus Operator中,则可以直接声明一个ServiceMonitor对象,把监听的服务和端口添加进来,这是ServiceMonitor关联服务对象过程。
脚本prometheus-serviceMonitor.yml内容如下所示:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: example-app
namespace: monitoring
labels:
team: frontend
spec:
namespaceSelector:
matchNames:
- default
selector:
matchLabels:
app: example-app
endpoints:
- port: web
通过定义selector中的标签定义选择监控目标的Pod对象,同时在endpoints中指定port名称为web的端口。默认情况下ServiceMonitor和监控对象必须是在相同Namespace下的。在本示例中由于Prometheus是部署在Monitoring命名空间下,因此为了能够关联default命名空间下的example对象,需要使用namespaceSelector定义让其可以跨命名空间关联ServiceMonitor资源。如果希望ServiceMonitor可以关联任意命名空间下的标签,则通过以下方式定义:
spec:
namespaceSelector:
any: true
(3)关联ServiceMonitor与Promethues
为了能够让Prometheus关联到ServiceMonitor,需要在Pormtheus定义中使用serviceMonitorSelector,我们可以通过标签选择当前Prometheus需要监控的ServiceMonitor对象,修改prometheus-inst.yaml中Prometheus的定义如下所示:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: inst
namespace: monitoring
spec:
serviceMonitorSelector:
matchLabels:
team: frontend
resources:
requests:
memory: 400Mi
更新prometheus服务:
kubectl apply -f prometheus-inst.yml
等待一会时间,在浏览器打开http://
虽然自动添加Job配置,但是Prometheus的Target中并没包含任何的监控对象。查看Prometheus的Pod实例日志,可以看到如下信息:
level=error ts=2019-08-14T10:01:27.707953281Z caller=klog.go:94 component=k8s_client_runtime func=ErrorDepth msg="/app/discovery/kubernetes/kubernetes.go:302: Failed to list *v1.Pod: pods is forbidden: User \"system:serviceaccount:monitoring:default\" cannot list pods at the cluster scope"
说明在monitoring名称空间下的prometheus没有权限获取defaul名称空间的example-app信息。
(4) 自定义ServiceAccount
为了提升权限获取defaul名称空间的服务信息,需要在Monitoring命名空间下为创建一个名为Prometheus的ServiceAccount,并且为该账号赋予相应的集群访问权限。
资源文件prometheus-rbac.yaml内容如下:
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitoring
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- nodes
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources:
- configmaps
verbs: ["get"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitoring
在完成ServiceAccount创建后,修改prometheus-inst.yaml,并添加ServiceAccount如下所示:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: inst
namespace: monitoring
spec:
serviceAccountName: prometheus
serviceMonitorSelector:
matchLabels:
team: frontend
resources:
requests:
memory: 400Mi
等待Prometheus Operator完成相关配置变更后,此时查看Prometheus,我们就能看到当前Prometheus已经能够正常的采集实例应用的相关监控数据了。
常用的grafana面板
| 监控类型 | grafana id |
|---|---|
| node-exproter(linux) | 8919 |
| windows-exproter(windows) | 10467 |
| mysql | 7362 |
| redis | 9338 |
| cadvisor(容器) | 893 |
grafana免密码登录设置,打开conf/defaults.ini,把auth.anonymous值改为true
[auth.anonymous]
enabled = true
参考:
专题「工具」的其它文章 »
- TLS和SSL (Nov 17, 2020)
- kubernetes基础和使用 (Sep 30, 2018)
- 使用gitlab和gitlab-runner实现DevOps (Sep 15, 2018)
- 一款漂亮的命令行工具——cmder (Sep 10, 2018)
- 搭建个人代码托管git服务 (Aug 19, 2018)
- 使用vagrant和vitrualBox搭建虚拟开发环境 (Aug 16, 2018)
- docker基础和使用 (Aug 10, 2018)
- goland IDE使用说明 (Aug 07, 2018)