kafka 基础
kafka 是一个开源的流处理平台,主要用于构建实时数据管道和流应用。它最初由LinkedIn开发,并在2011年成为Apache软件基金会的顶级项目。
kafka 架构
kafka 架构由存储层和计算层组成,如下图所示:
- 存储层旨在高效存储数据,并且是一个分布式系统,因此如果您的存储需求随着时间的推移而增长,您可以轻松扩展系统以适应增长。
- 计算层由生产者、消费者、流和连接器 API 四个核心组件组成,它们允许 kafka 跨分布式系统扩展应用程序。
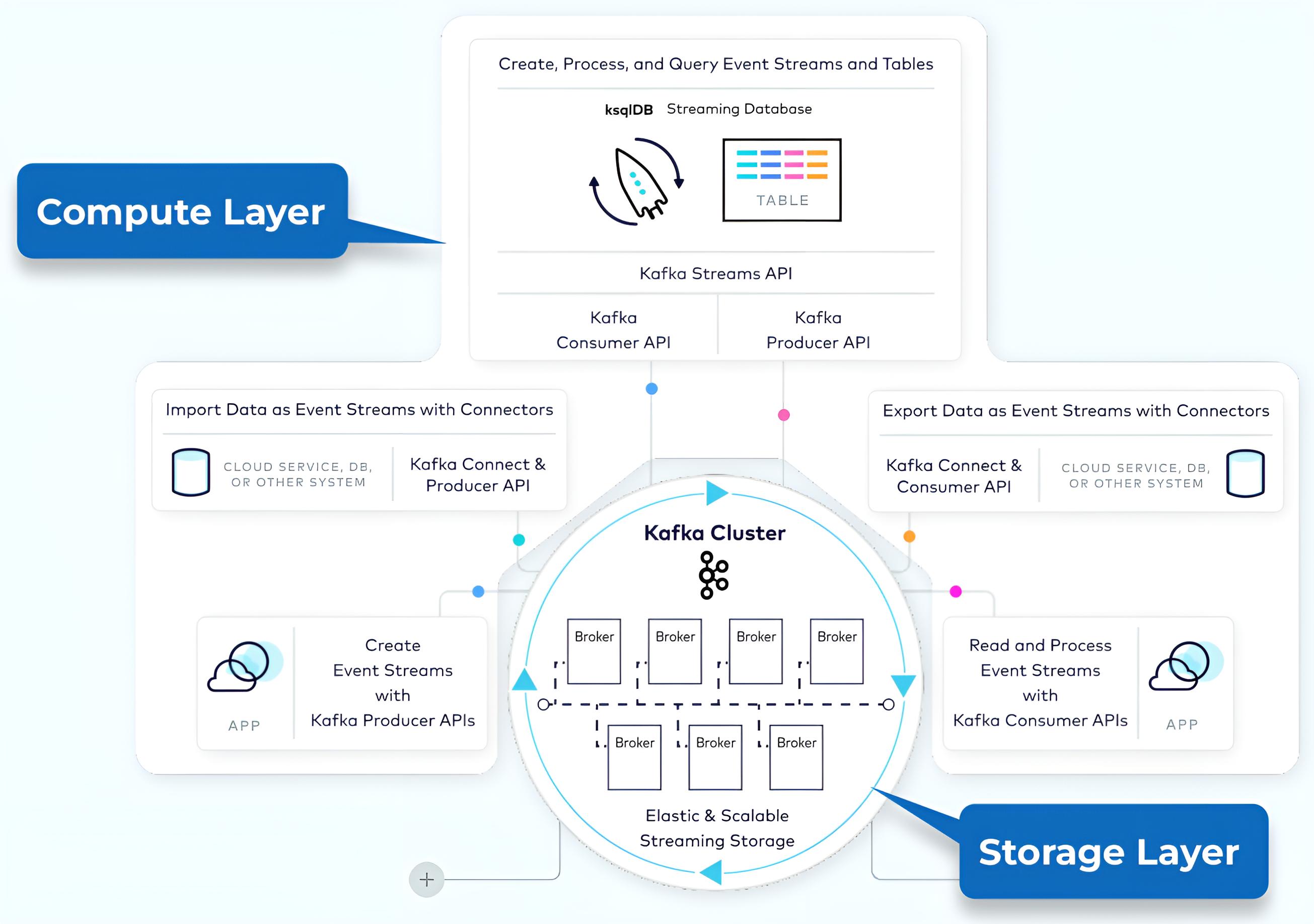
kafka 集群中的功能分为数据平面和控制平面,控制平面负责管理集群中的所有元数据,数据平面负责处理我们写入 kafka 和从 kafka 读取的实际数据。
kafka框架图:
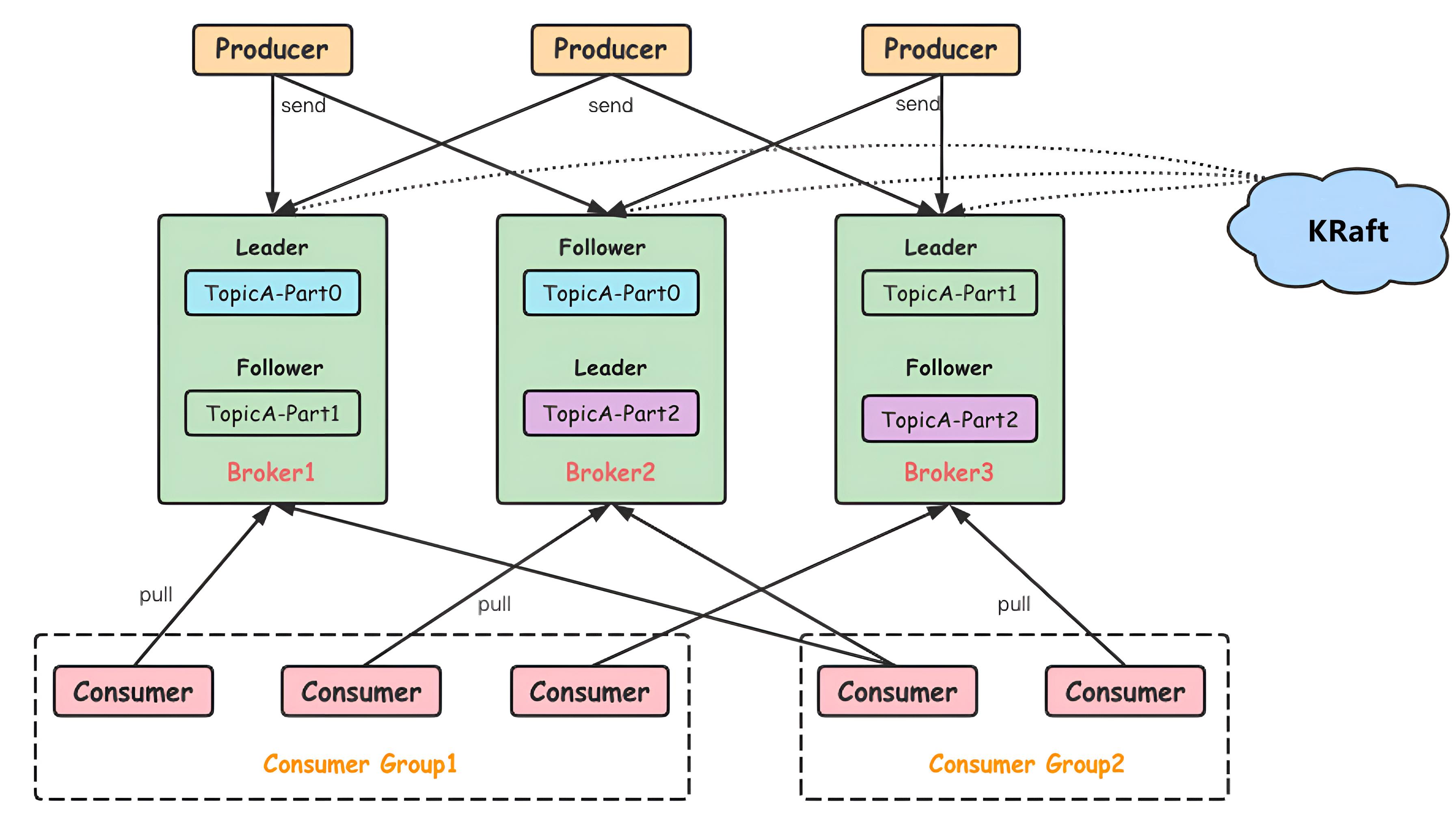
核心组件:
Producer(生产者)
- 负责发布消息到kafka的Topic中。
- 可以选择将消息发送到特定的Partition中,或由kafka的分区策略自动分配。
Consumer(消费者)
- 订阅一个或多个Topic,从中消费消息。
- 消费者通常会属于一个消费者组(Consumer Group),同一组中的消费者会共同分配并消费Topic的不同Partition中的消息,以实现负载均衡。
Broker
- kafka集群中的一个服务器称为Broker。
- Broker负责接收和存储消息,然后为消费者服务。
Topic
- 一个Topic可以看作是一个消息队列的名字。
- kafka中的数据流会被分类发布到不同的Topic中。
Partition(分区)
- 每个Topic可以分为多个Partition。
- 分区是kafka数据存储的基本单元,所有的消息都会写入一个有序的分区中。
Replica(副本)
- 为了确保数据的高可用性和容错性,每个Partition可以有多个副本。
- 副本分为Leader副本和Follower副本,Leader副本负责处理读写请求,Follower副本负责备份数据。
Kraft
- 替代传统的 ZooKeeper 作为元数据管理和分布式协调服务,简化运维、提高性能、增强安全性。
- 使用 Raft 协议来实现分布式一致性和协调,并内置在kafka,简化了系统架构。
kafka 中的 topic 始终是多生产者和多订阅者的:一个主题可以有零个、一个或多个向其写入事件的生产者;一个主题可以有零个、一个或多个订阅这些事件的消费者。
主题中的事件可以根据需要随时读取,与传统消息传递系统不同,事件在使用后不会被删除。相反,您可以通过每个主题的配置设置来定义 kafka 应保留事件多长时间,超过该时间后将丢弃旧事件。kafka 的性能在数据大小方面实际上是恒定的,因此长时间存储数据是完全没问题的。
topic 是分区的,这意味着topic分布在位于不同 kafka 代理上的多个“存储桶”中。这种数据的分布式放置对于可扩展性非常重要,因为它允许客户端应用程序同时从多个代理读取数据或向多个代理写入数据。当新事件发布到topic时,它实际上被附加到主题的某个分区中。具有相同事件键(例如客户或车辆 ID)的事件被写入同一个分区,kafka保证给定主题分区的任何消费者将始终按照写入顺序读取该分区的事件。
通过将 Topic 分为多个 Partition,可以实现消息的并行处理和存储,提升系统的吞吐量和可靠性。Broker 提供了 Partition 的物理存储和管理,每个 Partition 又存在多个副本以确保数据的安全性和高可用性。这种设计使得 kafka 能够高效地处理大规模的实时数据流。
kafka 数据复制
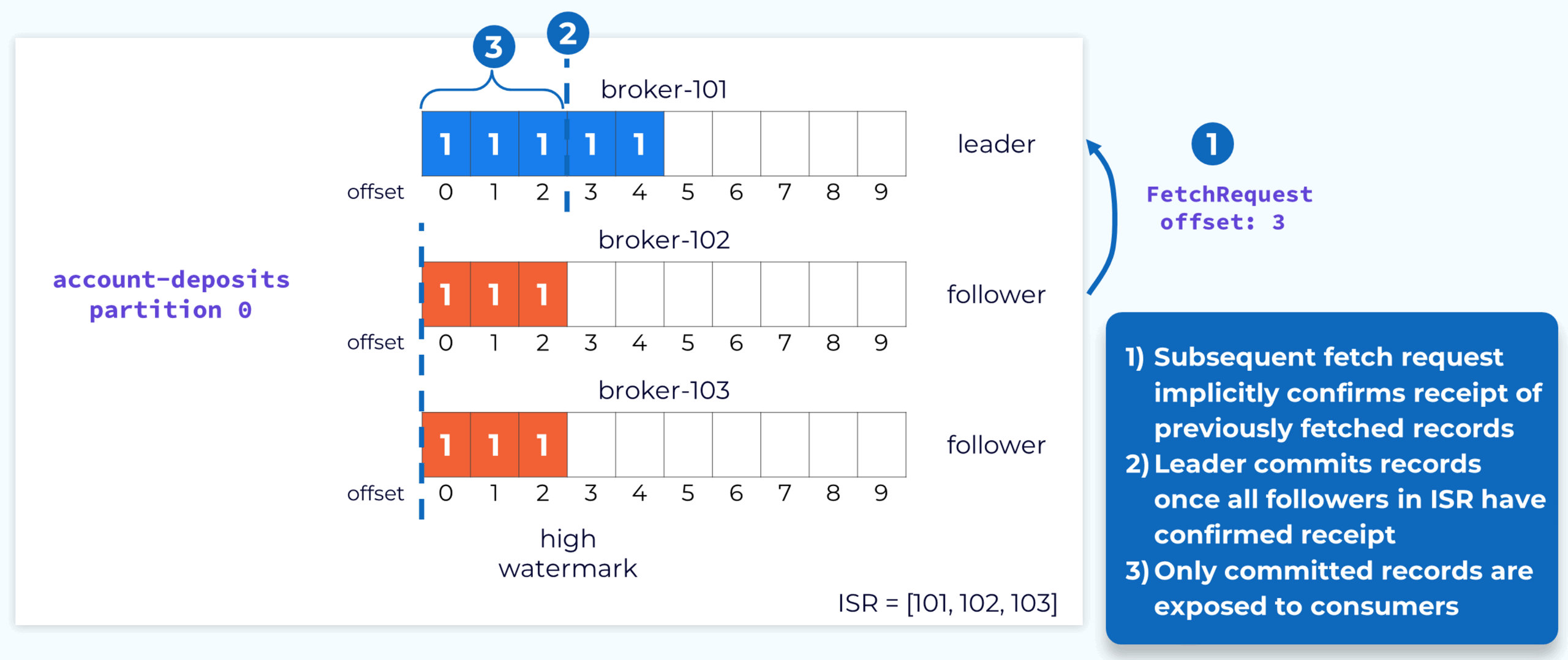
一旦创建了 topic 中所有分区的副本,每个分区的一个副本将被指定为领导者副本,而持有该副本的代理将成为该分区的领导者,其余副本将成为追随者。生产者将写入领导者副本,追随者将获取数据与领导者保持同步。消费者默认从领导者副本获取数据,但可以配置为从追随者获取数据。
领导者则使用获取响应来通知追随者当前的偏移量。由于此过程是异步的,追随者的偏移量通常会落后于领导者所持有的实际偏移量。
所有追随者都已获取到特定偏移量,则该偏移量之前的记录将被视为已提交并可供消费者使用。这是由偏移量指定的。
领导者监控其追随者的进度,如果从追随者上次完全赶上以来经过了可配置的时间量,领导者将从同步副本集中删除该追随者。这允许领导者推进偏移量,以便消费者可以继续使用当前数据。如果追随者重新上线或以其他方式采取行动并赶上领导者,那么它将被重新添加到 ISR。
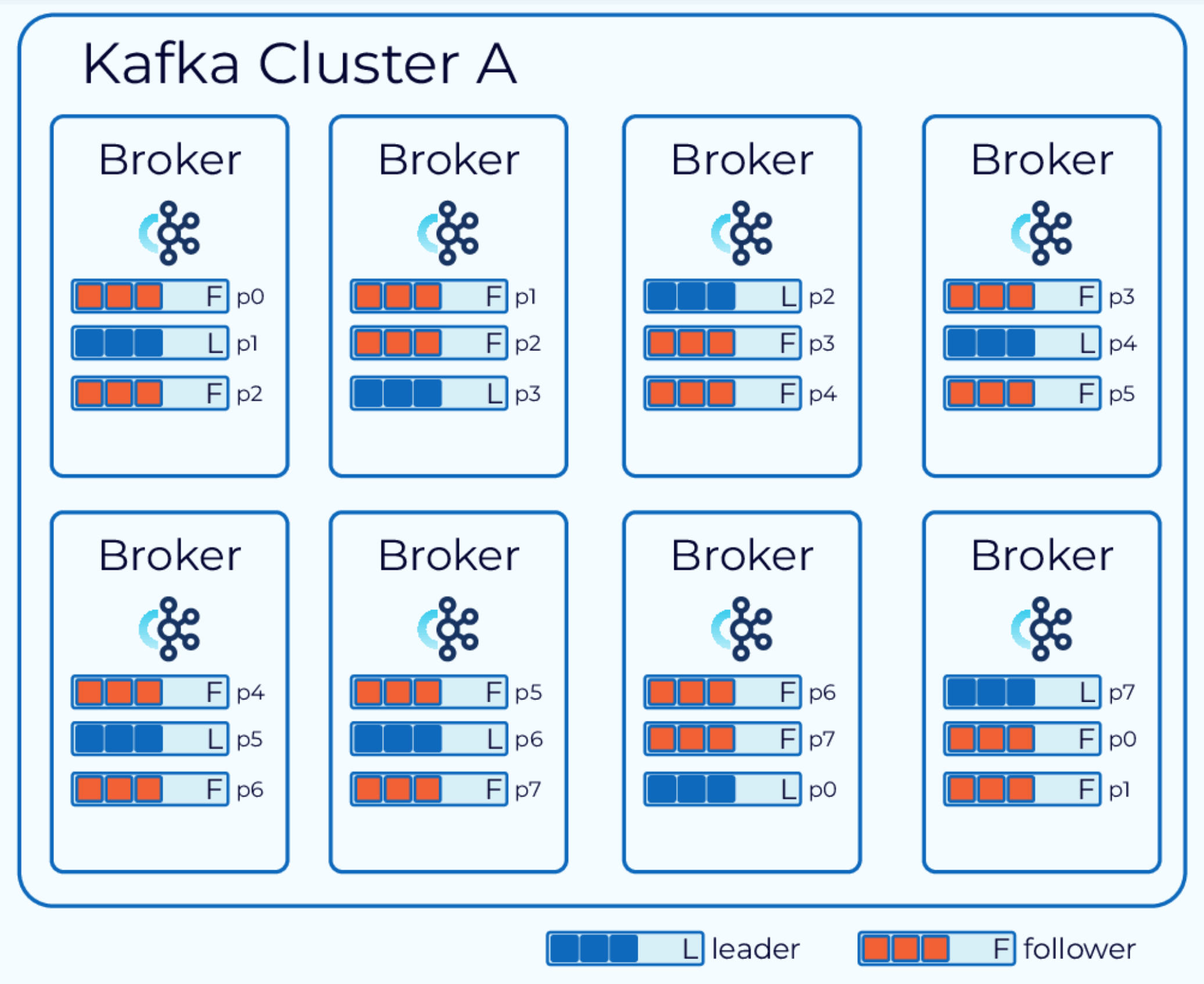
领导者副本的代理比追随者副本的工作量要多一些。因此,最好不要在单个代理上拥有过多的领导者副本。为了防止这种情况,kafka 有一个首选副本的概念。创建主题时,每个分区的第一个副本被指定为首选副本。由于 kafka 已经在努力在可用的代理之间均匀分布分区,因此这通常会导致领导者之间的良好平衡。
由于领导者选举会因各种原因而发生,领导者最终可能会出现在非首选副本上,这可能会导致不平衡。因此,kafka 将定期检查领导者副本是否存在不平衡。它使用可配置的阈值来做出此判断。如果确实发现不平衡,它将执行领导者重新平衡,以使领导者回到其首选副本上。
kafka 控制平面
kafka 3.3.1 以后版本使用KRaft替代Zookeeper,KRaft 模式有很多优点。
- 部署和管理更简单:由于只需安装和管理一个应用程序,kafka 的运营占用空间现在大大减少。这也使得在边缘的小型设备中利用 kafka 变得更加容易。
- 提高可扩展性:如图所示,使用 KRaft 的恢复时间比使用 ZooKeeper 快一个数量级。这使我们能够高效地扩展到单个集群中的数百万个分区。使用 ZooKeeper 时,有效限制为数万个。
- 更高效的元数据传播:基于日志、事件驱动的元数据传播可提高 kafka 许多核心功能的性能。
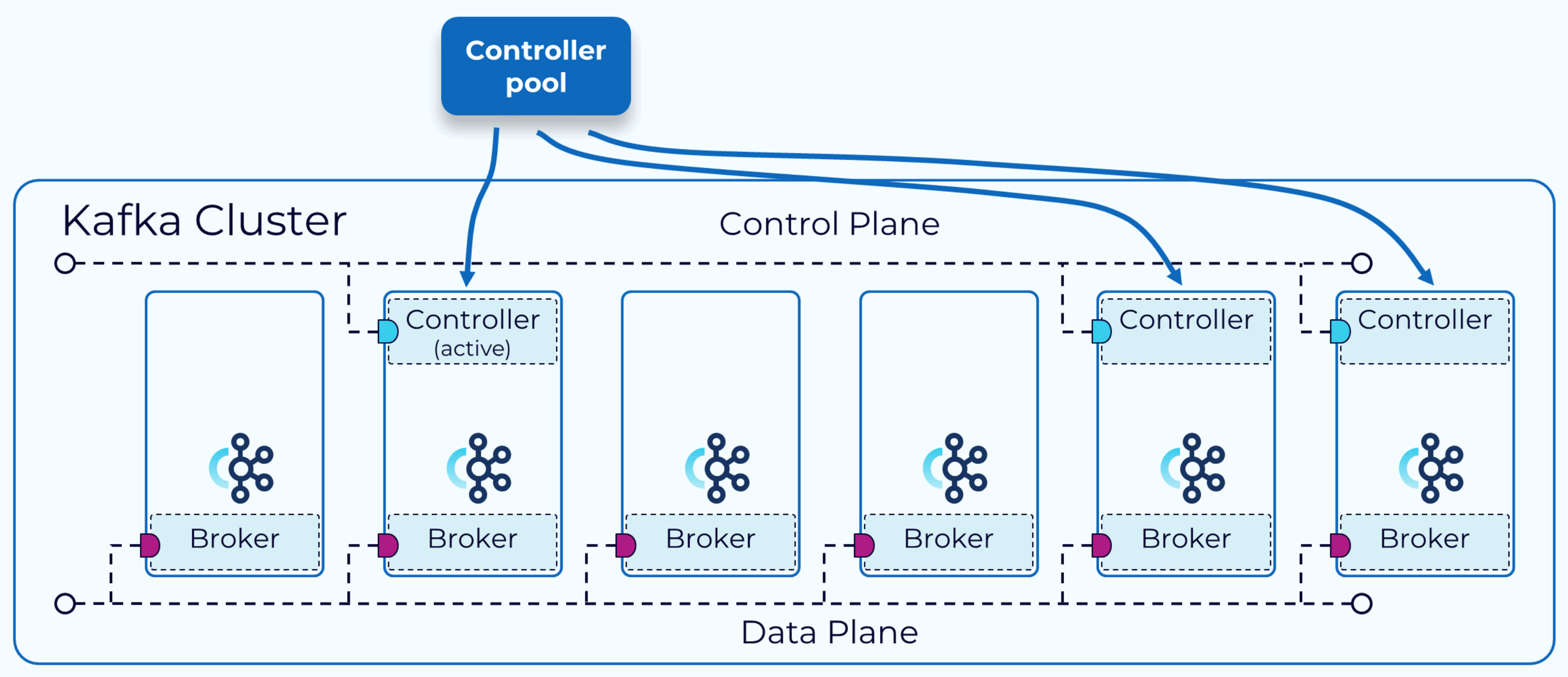
在 KRaft 模式下,kafka 集群可以以专用或共享模式运行。在专用模式下,一些节点会将其process.roles配置设置为controller,其余节点会将其设置为broker。对于共享模式,一些节点会将process.roles设置为controller 和 broker,这些节点将承担双重职责。选择哪种方式取决于集群的大小。
在启动kafka集群时以及当前领导者停止(无论是滚动升级还是由于故障)时都需要进行控制器领导者选举,通过投票请求、投票回应、达成共识三个步骤,当旧领导者控制器重新上线时,它跟随新领导者,并将其自己的元数据日志与领导者保持同步。
消费者组协议
kafka 将存储与计算分开,存储由代理处理,计算主要由消费者或基于消费者构建的框架(kafka Streams、ksqlDB)处理。消费者组在 kafka 消费者的有效性和可扩展性方面发挥着关键作用。
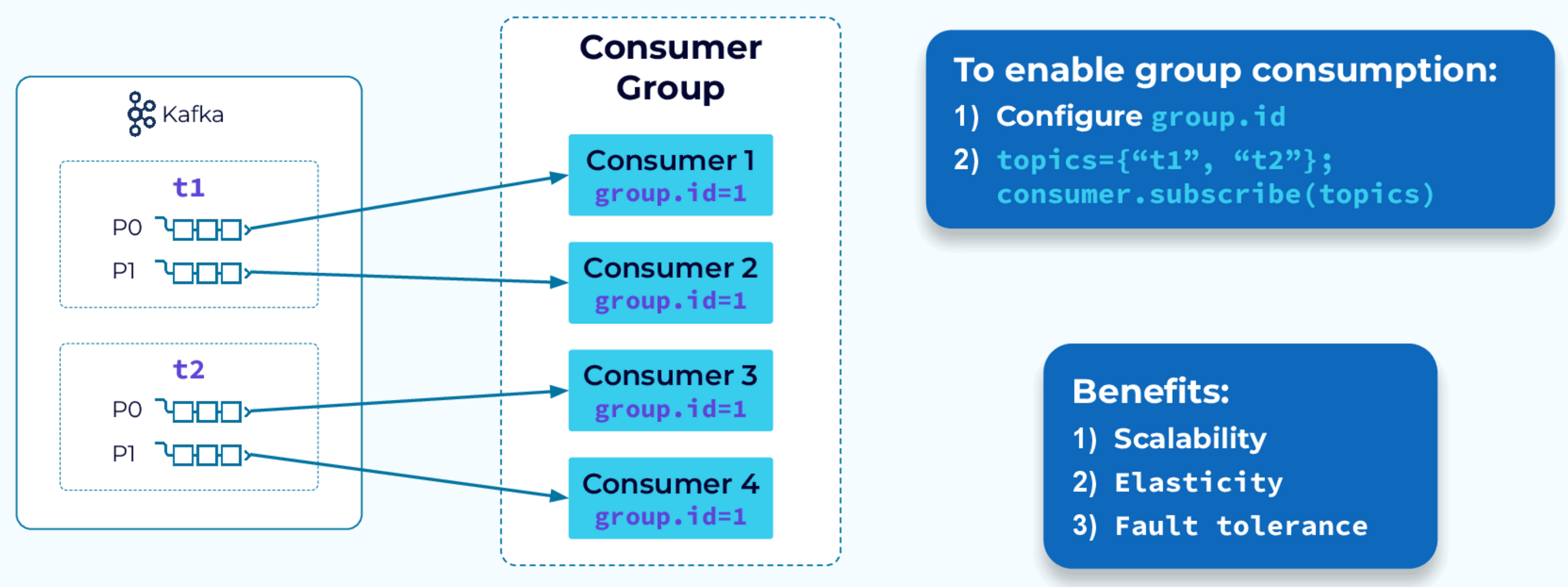
1. 消费者组的定义
消费者组是 kafka 中的一种机制,用于实现消息的并行处理和负载均衡。一个消费者组包含多个消费者实例,这些实例共同消费一个或多个主题(topic)的消息。
2. 消费者组的工作原理
- 负载均衡:kafka 将一个主题的分区(partition)分配给消费者组中的不同消费者实例,每个分区只会被组内的一个消费者消费。这种机制保证了消息的并行处理和负载均衡。
- 容错性:如果组内的某个消费者实例宕机,kafka 会自动将其分配的分区重新分配给其他消费者实例,保证消息的连续消费。
3. kafka 使用消费者组的原因
- 高吞吐量:通过消费者组,kafka 可以实现高吞吐量的消息处理,因为多个消费者实例可以并行处理不同的分区。
- 扩展性:消费者组使得 kafka 可以轻松扩展,只需增加更多的消费者实例即可。
- 容错性和高可用性:消费者组提供了自动故障转移和重新分配机制,增强了系统的容错性和高可用性。
消费者组再平衡是消费者组的一个关键特性,可能触发重新平衡的事件:
- 实例未能在超时之前向协调器发送心跳,因此被从组中删除
- 实例已添加到组中
- 已将分区添加到组订阅中的主题
- 某个组有通配符订阅,并且创建了新的匹配主题
- 最初的团队启动
注:对于静态组成员身份,每个消费者实例都会被分配一个group.instance.id,不发生重新平衡。
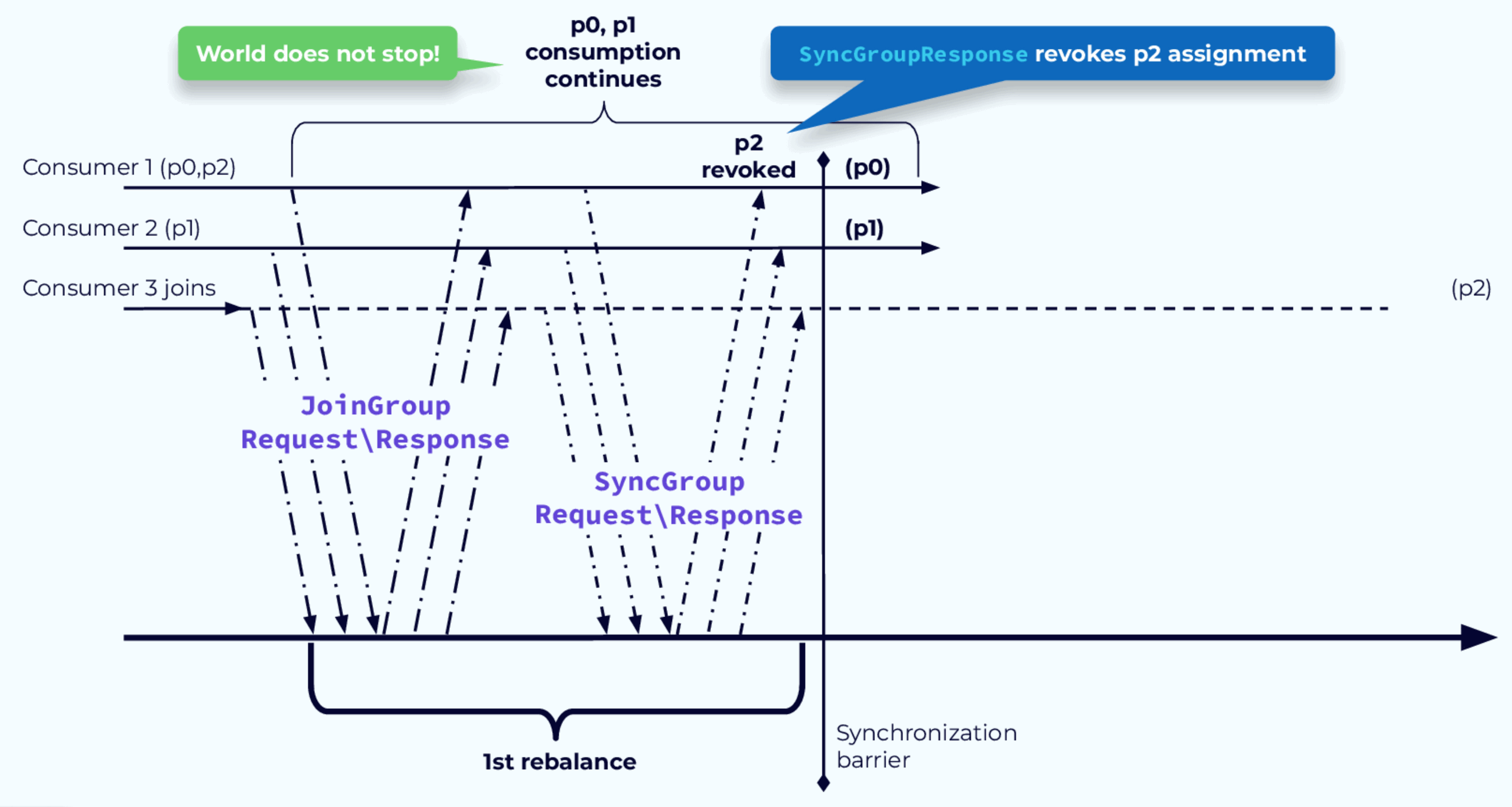
为了解决重新平衡时需要暂停处理的问题,引入了 CooperativeStickyAssignor 。此分配器的工作过程分为两个步骤。 - 确定需要撤销哪些分区分配。这些分配将在第一个重新平衡步骤结束时撤销。未撤销的分区可以继续处理。 - 被撤销的分区,它被分配给新的消费者。
数据持久性和可用性保证
生产者请求成功或失败的确认设置
生产者配置acks直接影响持久性保证,它还提供了持久性和延迟之间的几个权衡点之一。设置acks=0(也称为“即发即弃”模式)可提供较低的延迟,因为生产者不会等待代理的响应。但是,此设置无法提供强大的持久性保证,因为分区领导者可能由于暂时的连接问题而永远无法收到数据,或者我们可能正在经历领导者选举。
使用acks=1时,持久性会稍微好一些,因为知道数据已写入领导者副本,但延迟会稍微高一些,因为正在等待发送请求过程中的所有步骤。
最高级别的持久性来自 acks=all(或acks=-1),这也是默认设置。使用此设置,在数据写入领导者副本和 ISR(同步副本)列表中的所有追随者副本之前,不会确认发送请求。由于正在等待复制过程完成,因此延迟会更高。
主题级别配置min.insync.replicas与acks配置配合使用
两者配合使用可以更有效地实施持久性保证,此设置告知代理,除非 ISR 中有 N 个副本,否则不允许将事件写入主题。与acks=all结合使用,可确保在确认事件发送之前,主题上收到的任何事件都将存储在 N 个副本中。
例如复制因子为 3,并且min.insync.replicas 设置为 2,那么我们可以容忍一次故障,并且仍然接收新事件。如果丢失了两个节点,那么生产者发送请求将收到异常,通知生产者副本不足。生产者可以重试,直到有足够的副本,或者将异常冒泡。无论哪种情况,都不会丢失数据。
生产者幂等性
要启用幂等性,我们在生产者上设置enable.idempotence = true,这是 kafka 3.0 的默认值。使用此设置,生产者会用生产者 ID 和序列号标记每个事件。这些值将与事件一起发送并存储在日志中。如果由于故障而再次发送事件,则将包含相同的标识符。如果发送了重复事件,代理将看到生产者 ID 和序列号已经存在,并将拒绝这些事件并向客户端返回DUP响应。
因为生产者幂等性,kafka 具有顺序保证, 会过滤掉重复的事件,事件按发送顺序写入特定分区,消费者按相同顺序读取这些事件。
kafka 多副本机制中的一些重要术语:
- AR(Assigned Replicas):一个分区中的所有副本统称为 AR;
- ISR(In-Sync Replicas):Leader 副本和所有保持一定程度同步的 Follower 副本(包括 Leader 本身)组成 ISR;
- OSR(Out-of-Sync Raplicas):与 ISR 相反,没有与 Leader 副本保持一定程度同步的所有Follower 副本组成OSR;
一些 kafka 常见的应用场景
| 场景 | 场景描述 | 具体例子 |
|---|---|---|
| 日志收集 | kafka 常用于收集和聚合分布式系统中的日志数据,方便集中处理和分析。 | 网站日志收集,一个大型电商网站有多个服务器,每个服务器生成大量的访问日志。可以使用 kafka 将这些日志发送到一个集中的 kafka 集群,然后使用消费者从 kafka 中读取日志进行实时分析或存储到 HDFS 中进行离线分析。 |
| 微服务通信 | kafka 可以作为微服务之间的通信中介,确保服务之间的解耦和高可用性。 | 订单和通知服务,在一个微服务架构的电商平台中,订单服务可以将订单信息发送到 kafka,通知服务从 kafka 中消费订单信息并发送相应的通知(如短信或邮件)给用户。 |
| 消息队列 | kafka 可以作为消息队列系统,处理高吞吐量的消息传递。 | 订单处理系统,电商平台的订单处理系统可以使用 kafka 作为消息队列,将用户订单信息发送到 kafka,然后由多个消费者(如库存管理系统、支付系统)从 kafka 中读取订单信息进行处理。 |
| 数据管道 | kafka 常用于在不同的数据系统之间传输数据,充当数据管道。 | 数据同步,一个公司有多个数据库系统(如 MySQL 和 MongoDB),可以使用 kafka 将数据从一个数据库同步到另一个数据库,确保数据一致性。 |
| 事件溯源 | kafka 可以用于事件溯源,记录系统中发生的所有事件。 | 用户行为追踪,社交媒体平台使用 kafka 记录用户的所有行为(如点赞、评论、分享),然后可以基于这些事件数据进行用户行为分析和个性化推荐。 |
| 实时流处理 | kafka 可以与流处理框架(如 Apache Storm、Apache Flink 和 Apache Spark)结合使用,处理实时数据流。 | 实时监控,金融公司使用 kafka 来收集股票交易数据,并通过 Spark Streaming 实时处理这些数据,检测异常交易行为。 |
安装 kafka
安装单机版 kafka
安装kafaka集群有.env和docker-compose.yml两个文件。
.env文件内容如下:
# 把下面的 192.168.3.37 改为你的ip地址
ACCESS_ADDR=192.168.3.37:9092
docker-compose.yml内容如下:
version: '3.8'
services:
broker:
image: apache/kafka:3.7.0
container_name: broker
ports:
- '9092:9092'
environment:
kafka_NODE_ID: 1
kafka_LISTENER_SECURITY_PROTOCOL_MAP: 'CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT'
kafka_ADVERTISED_LISTENERS: 'PLAINTEXT_HOST://${ACCESS_ADDR},PLAINTEXT://broker:19092'
kafka_PROCESS_ROLES: 'broker,controller'
kafka_CONTROLLER_QUORUM_VOTERS: '1@broker:29093'
kafka_LISTENERS: 'CONTROLLER://:29093,PLAINTEXT_HOST://:9092,PLAINTEXT://:19092'
kafka_INTER_BROKER_LISTENER_NAME: 'PLAINTEXT'
kafka_CONTROLLER_LISTENER_NAMES: 'CONTROLLER'
CLUSTER_ID: '4L6g3nShT-eMCtK--X86sw'
kafka_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
kafka_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
kafka_TRANSACTION_STATE_LOG_MIN_ISR: 1
kafka_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
kafka_LOG_DIRS: '/var/lib/kafka/data'
volumes:
- $PWD/data/:/var/lib/kafka/data
kafka-ui:
image: provectuslabs/kafka-ui:v0.7.2
container_name: kafka-ui
ports:
- "18080:8080"
environment:
kafka_CLUSTERS_0_NAME: 'Local kafka Cluster'
kafka_CLUSTERS_0_BOOTSTRAPSERVERS: 'broker:19092'
DYNAMIC_CONFIG_ENABLED: "true"
depends_on:
- broker
第一次使用时,创建一个data文件夹作为数据持久化,并且修改目录data权限,
mkdir data
chmod -R 0777 data
打开.env文件,修改 kafka broker 外部访问地址,用于外部客户端连接,然后启动kafaka服务:
docker-compose up -d
启动服务成功后,可以在浏览器打开 http://localhost:18080 查看kafka信息。
安装 kafka 集群
安装kafaka集群有.env和docker-compose.yml两个文件。
.env文件内容如下:
# 把下面的 192.168.3.37 改为你的ip地址
kafka_1_ACCESS_ADDR=192.168.3.37:33001
kafka_2_ACCESS_ADDR=192.168.3.37:33002
kafka_3_ACCESS_ADDR=192.168.3.37:33003
docker-compose.yml内容如下:
version: "3.8"
services:
kafka-1:
image: docker.io/bitnami/kafka:3.7
container_name: kafka-1
ports:
- "33001:9092"
environment:
# KRaft settings
- kafka_CFG_NODE_ID=0
- kafka_CFG_PROCESS_ROLES=controller,broker
- kafka_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka-1:9093,1@kafka-2:9093,2@kafka-3:9093
- kafka_KRAFT_CLUSTER_ID=abcdefghijklmnopqrstuv
# Listeners
- kafka_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
#- kafka_CFG_ADVERTISED_LISTENERS=PLAINTEXT://:9092
- kafka_CFG_ADVERTISED_LISTENERS=PLAINTEXT://${kafka_1_ACCESS_ADDR}
- kafka_CFG_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT,CONTROLLER:PLAINTEXT
- kafka_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- kafka_CFG_INTER_BROKER_LISTENER_NAME=PLAINTEXT
# Clustering
- kafka_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR=3
- kafka_CFG_TRANSACTION_STATE_LOG_REPLICATION_FACTOR=3
- kafka_CFG_TRANSACTION_STATE_LOG_MIN_ISR=2
volumes:
- $PWD/data/kafka-1:/bitnami/kafka
networks:
- kafka-net
kafka-2:
image: docker.io/bitnami/kafka:3.7
container_name: kafka-2
ports:
- "33002:9092"
environment:
# KRaft settings
- kafka_CFG_NODE_ID=1
- kafka_CFG_PROCESS_ROLES=controller,broker
- kafka_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka-1:9093,1@kafka-2:9093,2@kafka-3:9093
- kafka_KRAFT_CLUSTER_ID=abcdefghijklmnopqrstuv
# Listeners
- kafka_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
#- kafka_CFG_ADVERTISED_LISTENERS=PLAINTEXT://:9092
- kafka_CFG_ADVERTISED_LISTENERS=PLAINTEXT://${kafka_2_ACCESS_ADDR}
- kafka_CFG_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT,CONTROLLER:PLAINTEXT
- kafka_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- kafka_CFG_INTER_BROKER_LISTENER_NAME=PLAINTEXT
# Clustering
- kafka_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR=3
- kafka_CFG_TRANSACTION_STATE_LOG_REPLICATION_FACTOR=3
- kafka_CFG_TRANSACTION_STATE_LOG_MIN_ISR=2
volumes:
- $PWD/data/kafka-2:/bitnami/kafka
networks:
- kafka-net
kafka-3:
image: docker.io/bitnami/kafka:3.7
container_name: kafka-3
ports:
- "33003:9092"
environment:
# KRaft settings
- kafka_CFG_NODE_ID=2
- kafka_CFG_PROCESS_ROLES=controller,broker
- kafka_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka-1:9093,1@kafka-2:9093,2@kafka-3:9093
- kafka_KRAFT_CLUSTER_ID=abcdefghijklmnopqrstuv
# Listeners
- kafka_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
#- kafka_CFG_ADVERTISED_LISTENERS=PLAINTEXT://:9092
- kafka_CFG_ADVERTISED_LISTENERS=PLAINTEXT://${kafka_3_ACCESS_ADDR}
- kafka_CFG_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT,CONTROLLER:PLAINTEXT
- kafka_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- kafka_CFG_INTER_BROKER_LISTENER_NAME=PLAINTEXT
# Clustering
- kafka_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR=3
- kafka_CFG_TRANSACTION_STATE_LOG_REPLICATION_FACTOR=3
- kafka_CFG_TRANSACTION_STATE_LOG_MIN_ISR=2
volumes:
- $PWD/data/kafka-3:/bitnami/kafka
networks:
- kafka-net
kafka-ui:
image: provectuslabs/kafka-ui:v0.7.2
restart: always
container_name: kafka-ui
ports:
- "18080:8080"
environment:
- kafka_CLUSTERS_0_NAME=Local-Kraft-Cluster
- kafka_CLUSTERS_0_BOOTSTRAPSERVERS=kafka-1:9092,kafka-2:9092,kafka-3:9092
- DYNAMIC_CONFIG_ENABLED=true
- kafka_CLUSTERS_0_AUDIT_TOPICAUDITENABLED=true
- kafka_CLUSTERS_0_AUDIT_CONSOLEAUDITENABLED=true
depends_on:
- kafka-1
- kafka-2
- kafka-3
networks:
- kafka-net
networks:
kafka-net:
第一次使用时,创建一个data文件夹作为数据持久化,并且修改目录data权限:
mkdir data/kafka-1 data/kafka-2 data/kafka-3
chmod -R 0777 data
打开.env文件,修改 kafka-1、kafka-2、kafka-3 外部访问地址,用于外部客户端连接,然后启动kafaka集群:
docker-compose up -d
启动服务成功后,可以在浏览器打开 http://localhost:18080 查看kafka信息。
使用go操作kafka示例
创建 topic 示例
package main
import (
"flag"
"fmt"
"github.com/IBM/sarama"
)
var (
brokerAddrs = []string{"192.168.3.37:33001", "192.168.3.37:33002", "192.168.3.37:33003"}
topic string
)
func main() {
flag.StringVar(&topic, "topic", "", "the name of the topic to create")
flag.Parsed()
if topic == "" {
fmt.Println("please specify the topic name, usage: go run main.go -topic <topic_name>")
return
}
// 创建kafka管理员客户端
admin, err := sarama.NewClusterAdmin(brokerAddrs, sarama.NewConfig())
if err != nil {
panic(err)
}
defer admin.Close()
// 创建主题
topicConfig := &sarama.TopicDetail{
NumPartitions: 3, // 分区数
ReplicationFactor: 1, // 副本数
ConfigEntries: map[string]*string{},
}
if err := CreateTopic(admin, topic, topicConfig); err != nil {
panic(err)
}
}
// IsTopicExists checks if a topic exists in the kafka cluster
func IsTopicExists(admin sarama.ClusterAdmin, topic string) bool {
topics, err := admin.ListTopics()
if err != nil {
return false
}
_, ok := topics[topic]
return ok
}
// CreateTopic creates a new topic in the kafka cluster, if topic already exists, it will ignore
func CreateTopic(admin sarama.ClusterAdmin, topic string, topicConfig *sarama.TopicDetail) error {
if IsTopicExists(admin, topic) {
return nil
}
err := admin.CreateTopic(topic, topicConfig, false)
if err != nil {
return err
}
fmt.Printf("topic %s created successfully\n", topic)
return nil
}
生产者示例
1. 同步生产者示例
package main
import (
"fmt"
"math/rand"
"time"
"github.com/IBM/sarama"
)
var (
brokerList = []string{"192.168.3.37:33001", "192.168.3.37:33002", "192.168.3.37:33003"}
topicName = "test_topic"
)
func main() {
// 创建kafka生产者配置
config := sarama.NewConfig()
// 设置kafka版本
// config.Version = sarama.V3_6_0_0
// ack类型 WaitForLocal(leader确认), WaitForAll(leader和follow都确认), NoResponse(不需确认)
config.Producer.RequiredAcks = sarama.WaitForAll
// 分区策略,默认是NewHashPartitioner、根据业务需要可以选择使用 NewRandomPartitioner、
//NewRoundRobinPartitioner、NewReferenceHashPartitioner、NewManualPartitioner。
config.Producer.Partitioner = sarama.NewHashPartitioner
config.Producer.Retry.Max = 5
// 成功交付的消息将在success channel返回
config.Producer.Return.Successes = true
config.ClientID = "kafka-demo"
// 创建同步生产者
producer, err := sarama.NewSyncProducer(brokerList, config)
if err != nil {
panic(err)
}
defer producer.Close()
// 发送的消息到指定主题
hostID := rand.Intn(1000)
for i := 1; i <= 50; i++ {
// 构造一个消息
message := &sarama.ProducerMessage{
Topic: topicName,
Value: sarama.StringEncoder(fmt.Sprintf("'%d log content %d'", hostID, i)),
Metadata: i,
}
// 发送消息
partition, offset, err := producer.SendMessage(message)
if err != nil {
panic(err)
}
fmt.Printf("send msg, topic=%s, partition=%d, offset=%d, i=%v\n", topicName, partition, offset, i)
}
<-time.After(time.Second * 2)
}
2. 异步生产者示例
package main
import (
"fmt"
"math/rand"
"time"
"github.com/IBM/sarama"
)
var (
brokerList = []string{"192.168.3.37:33001", "192.168.3.37:33002", "192.168.3.37:33003"}
topicName = "test_topic"
)
func main() {
// 创建kafka生产者配置
config := sarama.NewConfig()
// 设置kafka版本
// config.Version = sarama.V3_6_0_0
// ack类型 WaitForLocal(leader确认), WaitForAll(leader和follow都确认), NoResponse(不需确认)
config.Producer.RequiredAcks = sarama.WaitForLocal
// 分区策略,默认是NewHashPartitioner、根据业务需要可以选择使用 NewRandomPartitioner、
//NewRoundRobinPartitioner、NewReferenceHashPartitioner、NewManualPartitioner。
config.Producer.Partitioner = sarama.NewHashPartitioner
// 成功交付的消息将在success channel返回
config.Producer.Return.Successes = true
// 触发批量发送消息数设置
config.Producer.Flush.Messages = 10
config.Producer.Flush.Frequency = time.Second
// 创建异步生产者
producer, err := sarama.NewAsyncProducer(brokerList, config)
if err != nil {
panic(err)
}
defer producer.Close()
// 返回结果状态
go func() {
for {
select {
case pm := <-producer.Successes():
fmt.Printf("send msg, topic=%s, partition=%d, offset=%d, i=%v\n", pm.Topic, pm.Partition, pm.Offset, pm.Metadata)
case err := <-producer.Errors():
fmt.Printf("send msg failed, err: %v", err)
}
}
}()
// 发送的消息到指定主题
hostID := rand.Intn(1000)
count := 50
for i := 1; i <= count; i++ {
// 构造一个消息
message := &sarama.ProducerMessage{
Topic: topicName,
Value: sarama.StringEncoder(fmt.Sprintf("'%d log content %d'", hostID, i)),
Metadata: i,
}
// 发送消息
producer.Input() <- message
}
fmt.Println("send msg done")
<-time.After(time.Second * 2)
}
消费者示例
1. 消费者组示例
package main
import (
"context"
"fmt"
"time"
"github.com/IBM/sarama"
)
var (
brokerList = []string{"192.168.3.37:33001", "192.168.3.37:33002", "192.168.3.37:33003"}
groupID = "group1"
topicName = "test_topic"
)
func main() {
// 创建kafka消费者配置
config := sarama.NewConfig()
//config.Version = sarama.V3_6_0_0
config.Consumer.Offsets.Initial = sarama.OffsetOldest // 从未消费的消息开始消费,有可能重复消费
config.Consumer.Offsets.AutoCommit.Enable = true // true:自动提交偏移量,false:手动提交偏移量
config.Consumer.Offsets.AutoCommit.Interval = time.Second
// 创建kafka消费者组
cg, err := sarama.NewConsumerGroup(brokerList, groupID, config)
if err != nil {
panic(err)
}
defer cg.Close()
// 消费消息
ctx := context.Background()
autoCommit := config.Consumer.Offsets.AutoCommit.Enable
err = cg.Consume(ctx, []string{topicName}, &consumerHandler{autoCommit: autoCommit})
if err != nil {
fmt.Printf("consume error: %v\n", err)
}
}
// Setup 、 Cleanup 和 ConsumeClaim 是 s.handler.ConsumeClaim 的三个接口,需要用户自己实现。
// 可以简单理解为,当需要创建一个会话时,先运行 Setup ,然后在 ConsumeClaim 中处理消息,最后运行 Cleanup 。
type consumerHandler struct {
autoCommit bool
}
func (h *consumerHandler) Setup(sess sarama.ConsumerGroupSession) error {
fmt.Println("setup topic:partitions -->", sess.Claims()) // 当有新的消费者加入或退出消费者组时,动态平衡后后可以看到本消费者所负责的分区
return nil
}
func (h *consumerHandler) Cleanup(sess sarama.ConsumerGroupSession) error {
fmt.Println("cleanup topic:partitions -->", sess.Claims())
return nil
}
func (h *consumerHandler) ConsumeClaim(sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
fmt.Printf("received msg: topic=%s, partition=%d, offset=%d, key=%s, val=%s\n", msg.Topic, msg.Partition, msg.Offset, msg.Key, msg.Value)
sess.MarkMessage(msg, "")
if !h.autoCommit {
sess.Commit()
}
}
return nil
}
2. 分区消费示例
package main
import (
"fmt"
"github.com/IBM/sarama"
)
var (
brokerList = []string{"192.168.3.37:33001", "192.168.3.37:33002", "192.168.3.37:33003"}
topicName = "test_topic"
)
func main() {
// 创建kafka消费者配置
config := sarama.NewConfig()
config.Version = sarama.V3_6_0_0
config.Consumer.Return.Errors = true
// 创建kafka消费者
consumer, err := sarama.NewConsumer(brokerList, config)
if err != nil {
panic(err)
}
defer consumer.Close()
// 根据topic取到所有的分区
partitionList, err := consumer.Partitions(topicName)
if err != nil {
panic(err)
}
// 消费的主题
for _, partition := range partitionList {
offset := sarama.OffsetNewest // 可以设置为指定偏移量、最新偏移量sarama.OffsetNewest、历史偏移量sarama.OffsetOldest
go func(partitionID int32, offset int64) {
pc, err := consumer.ConsumePartition(topicName, partitionID, offset)
if err != nil {
panic(err)
}
defer pc.Close()
for {
select {
case msg := <-pc.Messages():
fmt.Printf("received msg: topic=%s, partition=%d, offset=%d, key=%s, val=%s\n", msg.Topic, msg.Partition, msg.Offset, msg.Key, msg.Value)
case err := <-pc.Errors():
fmt.Println("consuming err:", err)
}
}
}(partition, offset)
}
select {}
}
获取 topic 堆积数量示例
topic堆积数量是比较重要的一个指标,直接影响业务的进行,可以在从kafka服务中该指标,也可以实现一个简单客户端从kafka或该指标。
package main
import (
"fmt"
"github.com/IBM/sarama"
)
var (
brokerList = []string{"192.168.3.37:33001", "192.168.3.37:33002", "192.168.3.37:33003"}
topic = "test_topic"
groupID = "test_group"
)
// ClientManager client manager
type ClientManager struct {
client sarama.Client
offsetManager sarama.OffsetManager
}
// Backlog info
type Backlog struct {
Partition int32 `json:"partition"` // partition id
Backlog int64 `json:"backlog"` // data backlog
NextConsumeOffset int64 `json:"nextOffset"` // offset for next consumption
}
// InitClientManager init client manager
func InitClientManager(addrs []string, groupID string) (*ClientManager, error) {
config := sarama.NewConfig()
//config.Version = sarama.V3_6_0_0
client, err := sarama.NewClient(addrs, config)
if err != nil {
return nil, err
}
offsetManager, err := sarama.NewOffsetManagerFromClient(groupID, client)
if err != nil {
return nil, err
}
return &ClientManager{
client: client,
offsetManager: offsetManager,
}, nil
}
// GetBacklog get topic backlog
func (m *ClientManager) GetBacklog(topic string) (int64, []*Backlog, error) {
var (
total int64 = 0
partitionBacklogs []*Backlog
)
partitions, err := m.client.Partitions(topic)
if err != nil {
return 0, nil, err
}
for _, partition := range partitions {
// get offset from kafka
offset, err := m.client.GetOffset(topic, partition, -1)
if err != nil {
return 0, nil, err
}
// create topic/partition manager
pom, err := m.offsetManager.ManagePartition(topic, partition)
if err != nil {
return 0, nil, err
}
var backlog int64
// call sarama The NextOffset method of PartitionOffsetManager. Return the offset for the next consumption
// if the consumer group has not consumed the data for this section, the return value will be -1
n, str := pom.NextOffset()
if str != "" {
return 0, nil, fmt.Errorf("partition %d, %s", partition, str)
}
if n == -1 {
backlog = offset
} else {
backlog = offset - n
}
total += backlog
partitionBacklogs = append(partitionBacklogs, &Backlog{
Partition: partition,
Backlog: backlog,
NextConsumeOffset: n,
})
}
return total, partitionBacklogs, nil
}
// Close topic backlog
func (m *ClientManager) Close() error {
if m != nil && m.client != nil {
return m.client.Close()
}
return nil
}
func main() {
m, err := InitClientManager(brokerList, groupID)
if err != nil {
panic(err)
}
defer m.Close()
total, backlogs, err := m.GetBacklog(topic)
if err != nil {
panic(err)
}
fmt.Println("total backlog:", total)
for _, backlog := range backlogs {
fmt.Printf("partation=%d, backlog=%d, next_consume_offset=%d\n", backlog.Partition, backlog.Backlog, backlog.NextConsumeOffset)
}
}
总结
kafka 作为一个分布式流处理平台,应用非常广泛,尤其是在大数据处理领域,它以其高吞吐量、低延迟、可扩展性等特点,成为构建实时数据处理应用的首选平台之一。在使用 kafka 的过程中,需要了解一些kafka相关知识:
1. 深入理解 kafka 的核心概念
kafka 的核心概念包括主题、分区、消费者组、偏移量等。理解这些概念对于理解 kafka 的工作原理和使用 kafka 进行开发至关重要。
2. 掌握 kafka 的基本操作
kafka 提供了丰富的 API 来进行消息的发布和消费。掌握这些 API 是使用 kafka 的基础。
3. 了解 kafka 的常见应用场景
kafka 可以应用于各种场景,例如日志收集、数据分析、实时流处理等。了解 kafka 的常见应用场景可以帮助我们更好地选择 kafka 进行应用开发。
4. 关注 kafka 的性能优化
kafka 的性能优化是一个重要的课题。通过合理的配置和优化,可以提高 kafka 的吞吐量和降低延迟。
5. 学习 kafka 的生态系统
kafka 拥有丰富的生态系统,包括各种工具、框架和库。学习 kafka 的生态系统可以帮助我们更好地使用 kafka。
- 官网: https://kafka.apache.org/
- 文档:https://kafka.apache.org/documentation/#gettingStarted
- go SDK:https://github.com/IBM/sarama
- go SDK示例:https://github.com/IBM/sarama/tree/main/examples
总而言之,kafka 是一门强大的工具,可以帮助我们构建实时数据处理应用。通过深入学习和掌握 kafka 的相关知识和技能,我们可以充分发挥 kafka 的优势,为我们的业务带来价值。
专题「消息中间件」的其它文章 »
- rabbitmq基础和使用 (Jun 20, 2019)