接着上一篇文章 一天多开发完成一个极简版社区后端服务 ,接下来使用工具sponge实战一个微服务集群项目community-cluster,点击查看community-cluster的完整项目代码,
单体服务community-single拆分为微服务具体过程
社区后端服务community-single采用单体web应用架构,为了应对需求增加,造成功能越来越复杂,代码维护和开发变得困难的问题,把community-single拆分成多个微服务,下面是拆分微服务具体步骤:
第一步是进行系统分析和设计。首先确定哪些功能模块适合独立作为微服务,需要对单体服务community-single进行了仔细的功能分解,将其划分为几个关键的领域,分为用户服务(user)、关系服务(relation)和内容创作服务(creation)三个独立的服务。用户服务负责用户注册登录等功能,关系服务负责好友关系管理等,内容创作服务负责帖子创建、评论、点赞、收藏等功能。这些领域代表了系统的核心功能,并且在不同的领域之间存在较强的逻辑隔离。
第二步是定义服务接口。每个微服务需要定义清晰的RPC接口供外部调用,接口需要指定输入输出的数据结构。每个服务开发团队需要根据业务设计自己的接口并完成接口文档。
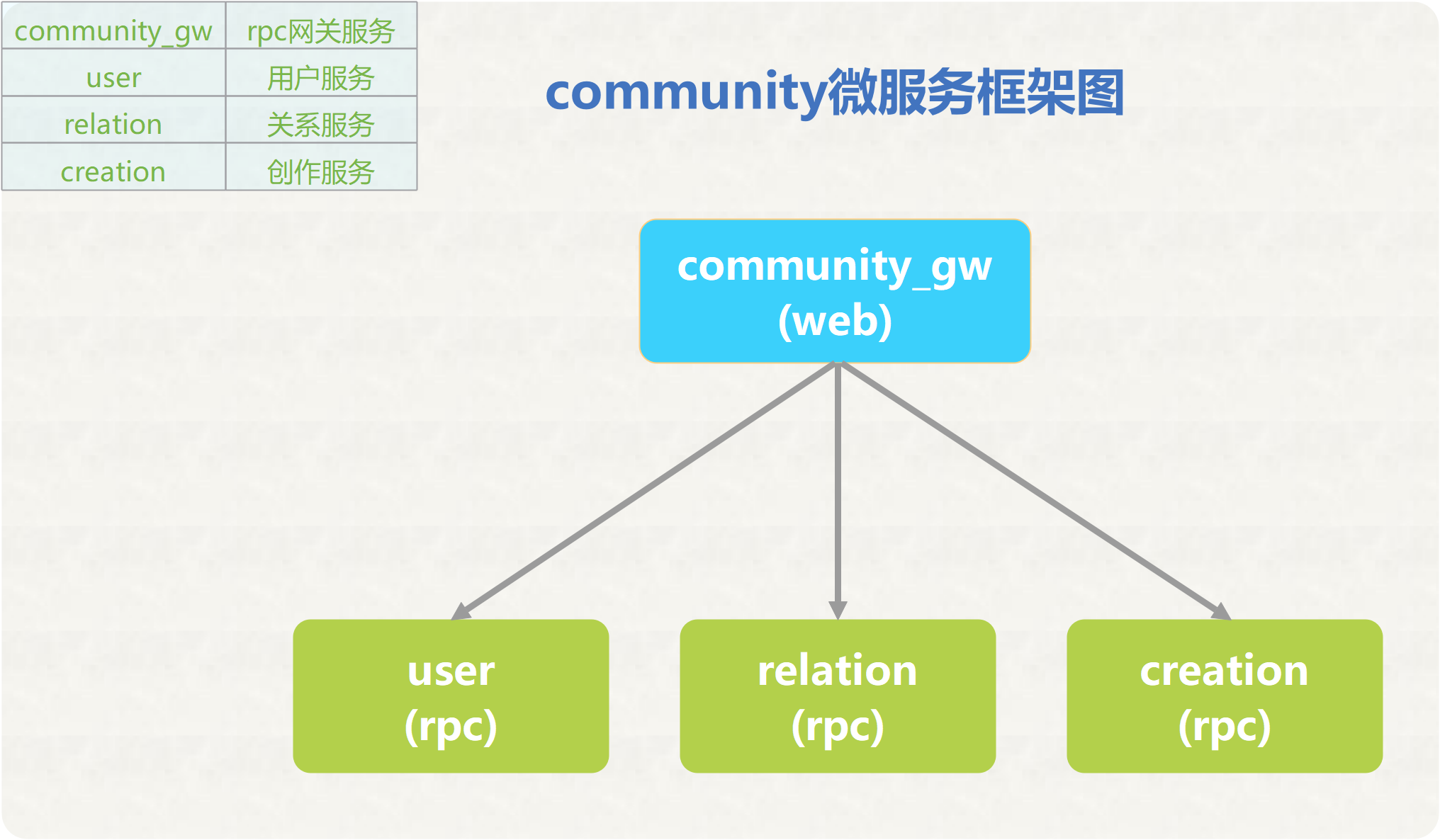
第三步是设计集群架构。引入了一个rpc网关服务(community_gw),rpc网关服务作为所有微服务的入口,负责路由请求和负载均衡,它可以根据请求的路由信息将请求转发给相应的微服务。此外,rpc网关服务还提供了身份验证、授权和安全性等共享功能,以确保系统的安全性和一致性,这种架构可以提高整体的扩展性。
第四步是数据迁移。单体服务community-single使用的单一数据库,现在需要将数据按服务拆分,迁移至每个微服务自己的数据存储中。这里用户服务、关系服务、创作服务使用独立的MySQL,实现各自的数据隔离。
第五步是开发、测试、部署微服务。在拆分后的微服务集群中,每个微服务都可以独立进行。团队成员可以专注于自己领域的开发工作,并且可以根据需求对各个微服务进行水平扩展,以满足不同的性能需求。此外,微服务架构还提供了更好的可扩展性,提供持续集成和持续交付(CI/CD),以快速部署和发布新的功能和更新。微服务上线后,需要全面测试各个微服务的功能,确保拆分后的服务可以正常运行、RPC调用正常、满足预期功能。
最后是流量迁移。当微服务架构正常运行后,将外部流量逐步迁移至新的RPC网关层,停止对community-single的访问,完成从单体架构到微服务架构的过渡。后端服务的扩展和升级将主要在微服务层进行。
通过上述步骤,将单体服务community-single拆分为微服务是一个复杂而耗时的过程,通过系统分析、功能拆分、技术选型、API设计和迁移策略等步骤,实现系统的微服务化,并提升系统的可扩展性、可靠性和性能。微服务架构也带来了分布式事务、运维成本增加等新的挑战,需要综合考虑多个因素。通过持续的评估和优化,可以不断提升系统的灵活性和可维护性,以适应不断变化的业务需求。
community-cluster 介绍
community-cluster是由 gRPC服务 和 rpc网关服务 这两种服务类型组成,gRPC服务是各个功能的实现模块,rpc网关服务主要作用是转发请求给gRPC服务和组装数据。community-cluster服务集群由工具sponge搭建,sponge生成gRPC服务和rpc网关服务代码时都会自动剥离业务逻辑与非业务逻辑两部分代码,剥离业务逻辑与非业务逻辑的好处是让开发者聚焦在核心业务逻辑代码中,极大的减小搭建微服务集群的难度,减少人工编写大量代码。框架图如下图所示:
gRPC服务代码组成结构基于grpc封装,包括了丰富的服务治理插件、构建、部署脚本,gRPC服务代码组成结构如下图所示:
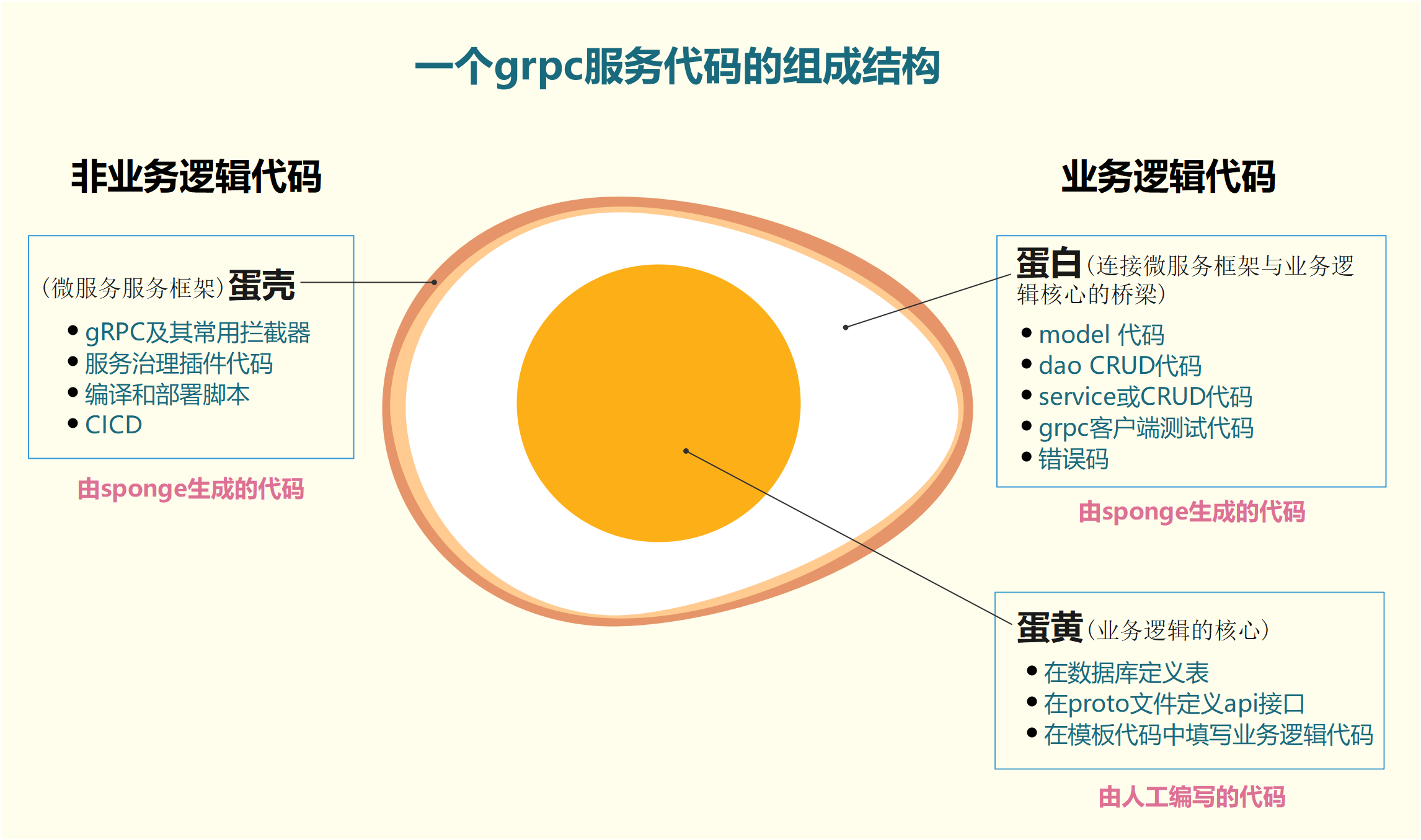
图1 gRPC服务代码结构图
从图1可以看出,开发一个完整的微服务聚焦在定义数据表、定义api接口、在模板代码中编写具体业务逻辑代码这3个节点上,而这3个节点代码在单体web服务community-single已经存在,不需要重新编写,直接把这些代码移植过来即可,也就是蛋黄(核心业务逻辑代码)保持不变,只需换蛋壳(web框架换成gRPC框架)和蛋白(http handler相关代码换成rpc service相关代码),使用工具sponge,很容易完成web服务到gRPC服务的转换。
rpc网关服务代码基于gin封装,包括了丰富的服务治理插件、构建、部署脚本,rpc网关服务代码组成结构如下图所示:
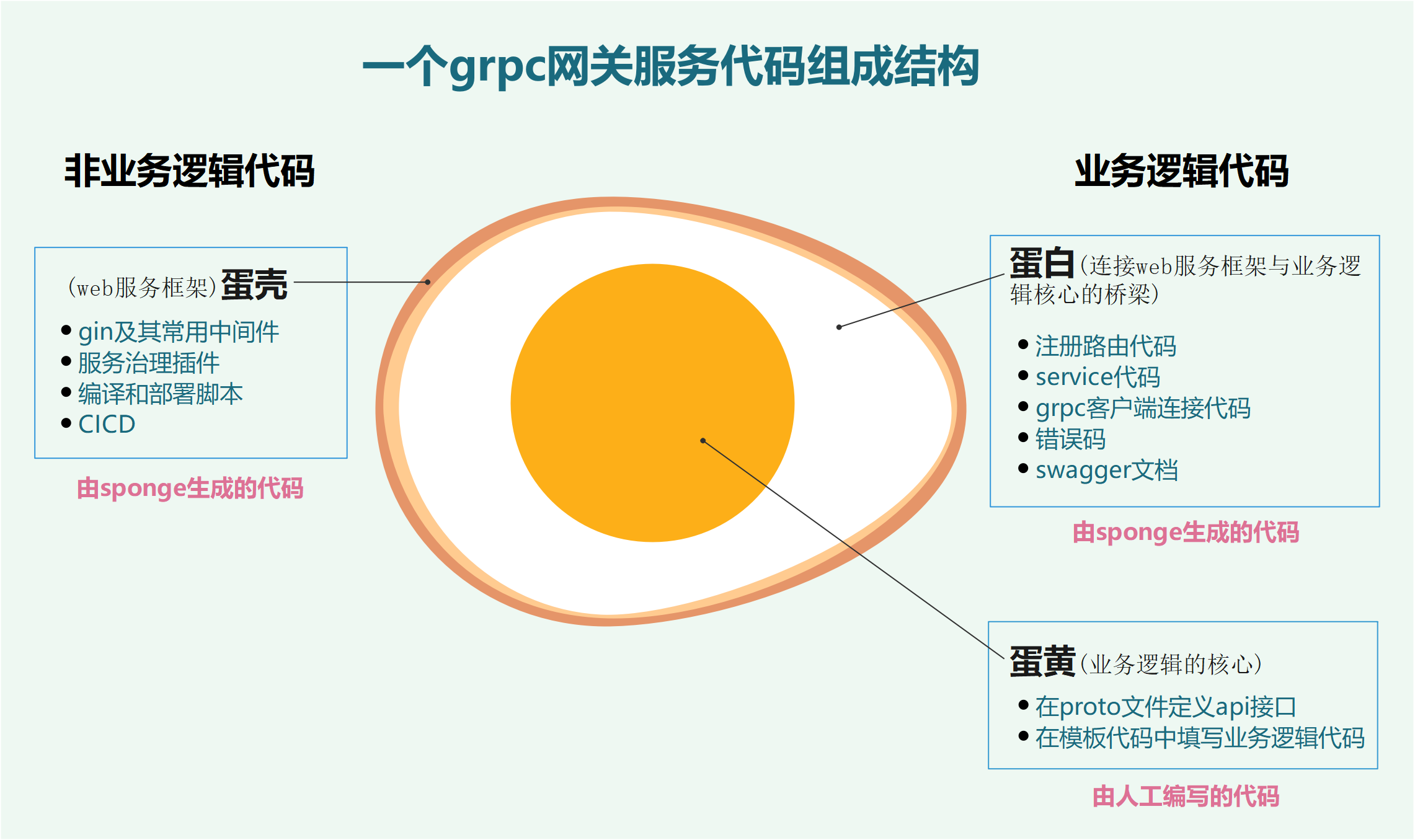
图2 rpc网关服务代码结构图
从图2可以看出,开发一个完整rpc网关服务聚焦在定义api接口、在模板代码中编写具体业务逻辑代码这2个节点上,其中定义api接口在单体web服务community-single已经存在,不需要重新编写,复制proto文件过来就可以使用。
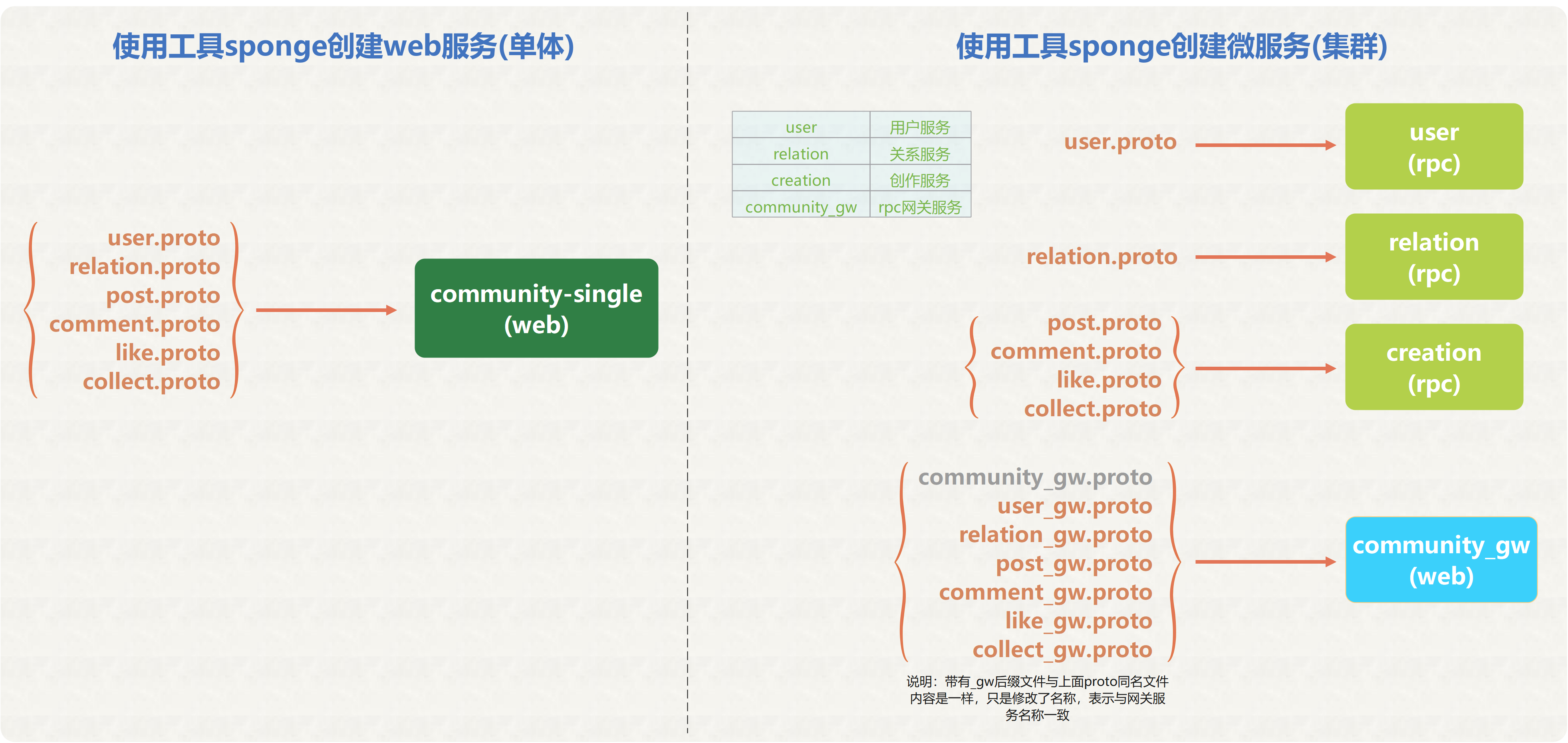
这是单体web服务和微服务集群依赖的proto文件对比图,左边是单体web服务依赖的proto文件,所有proto文件都在同一个服务中。右边是微服务依赖的proto文件,根据各个gRPC服务依赖自己的proto文件。
在rpc网关服务中,如果需要从多个微服务中获取的数据组装成一个新的api接口,把这个组装的新api接口描述信息填写到community_gw.proto文件中。
下面使用工具sponge从0开始到完成微服务集群过程,开发过程依赖工具sponge,需要先安装sponge,点击查看安装说明。
创建一个目录community-cluster,把各个独立微服务代码移动到这个目录下。
gRPC服务
创建user、relation、creation服务
进入sponge的UI界面,点击左边菜单栏【Protobuf】–> 【RPC类型】–>【创建rpc项目】,填写参数,分别生成三个微服务代码。
创建user服务
这是从单体服务community-single复制过来的proto文件user.proto,用来快速生成用户(user)服务代码,如下图所示:
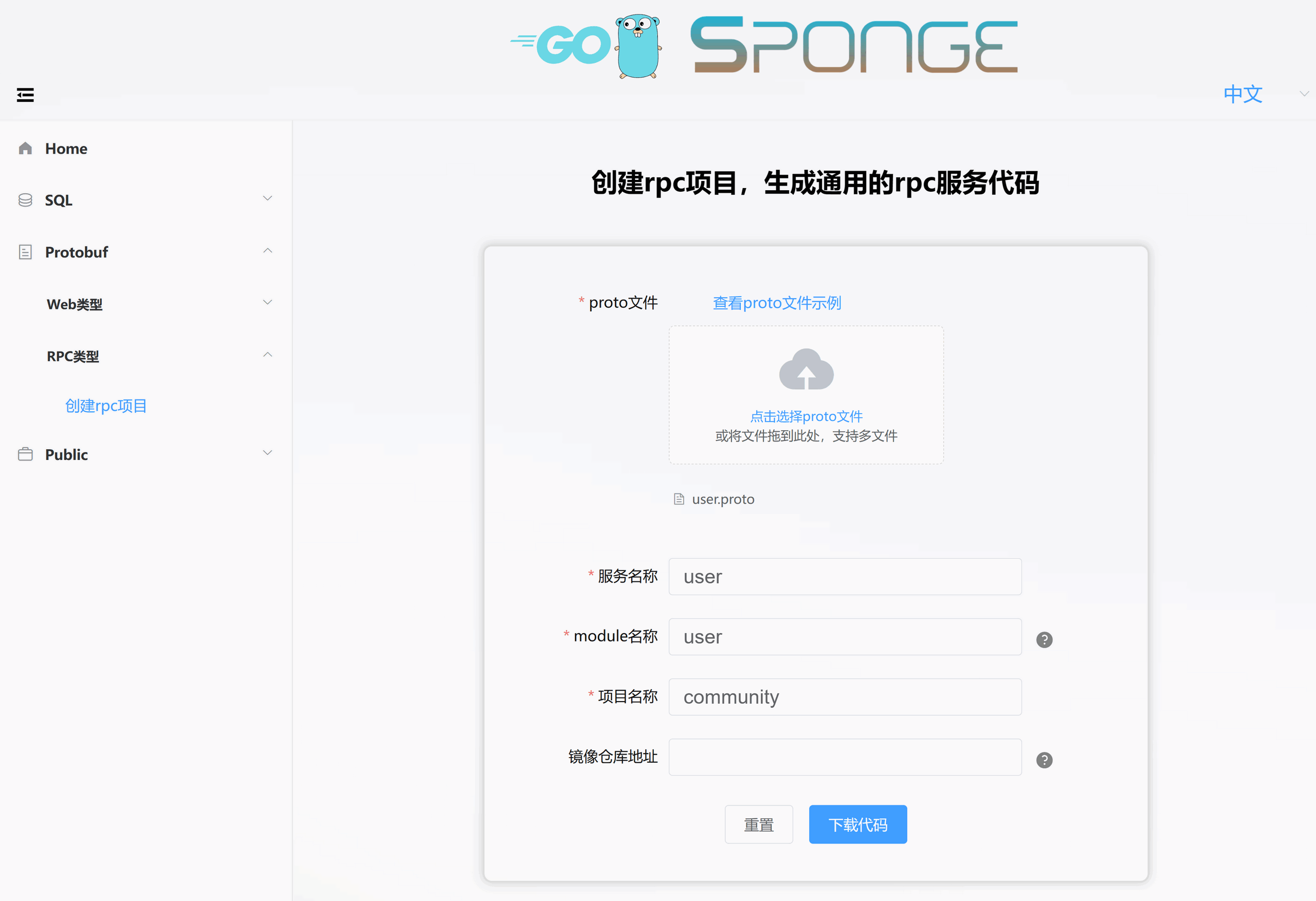
解压代码,把目录名称改为user,然后把user目录移动community-cluster目录下。
创建relation服务
这是从单体服务community-single复制过来的proto文件relation.proto,用来快速生成关系(relation)服务,如下图所示:
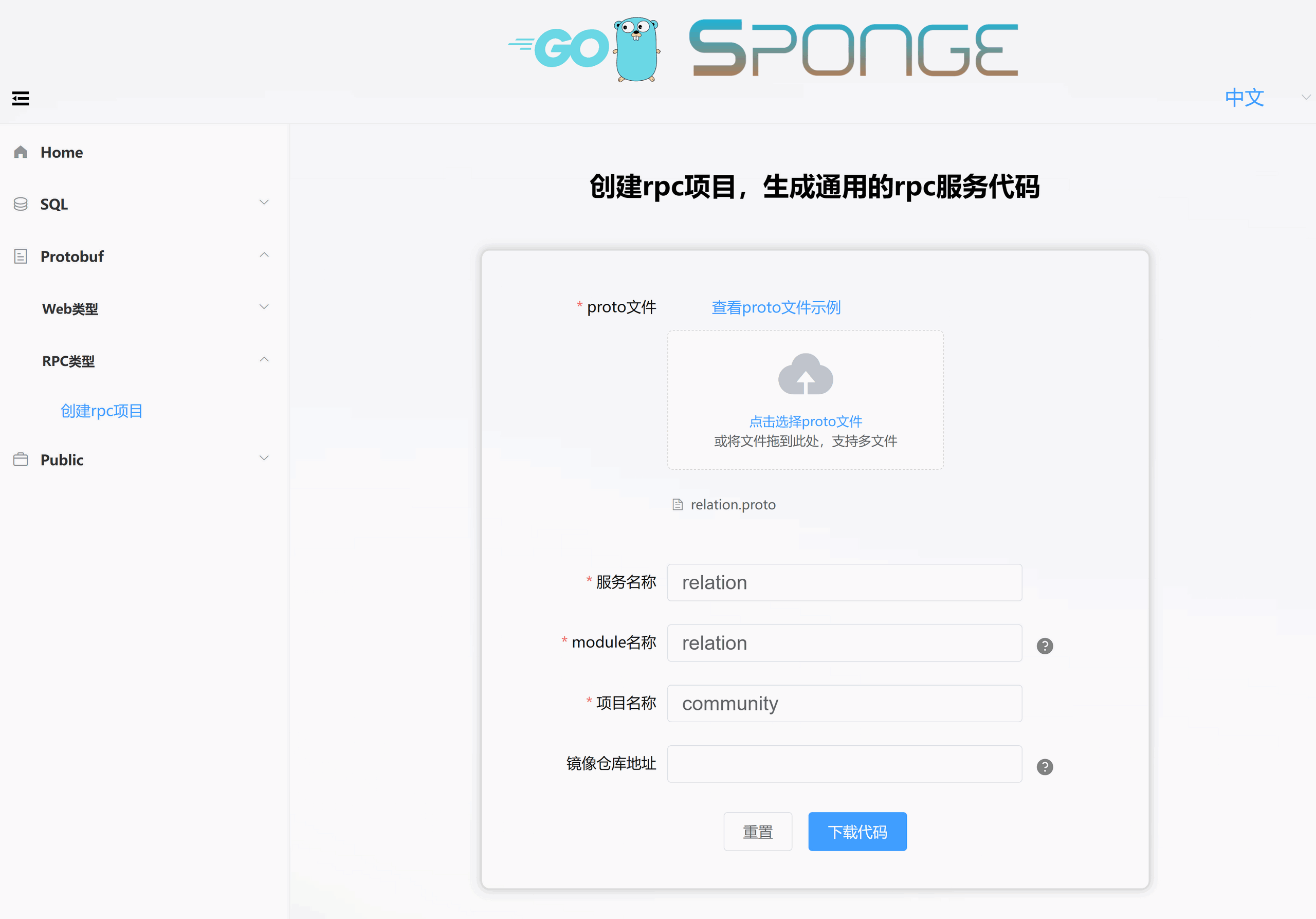
解压代码,把目录名称改为relation,然后把relation目录移动community-cluster目录下。
创建creation服务
这是从单体服务community-single复制过来的proto文件post.proto、comment.proto、like.proto、collect.proto,快速生成创作(creation)服务,如下图所示:
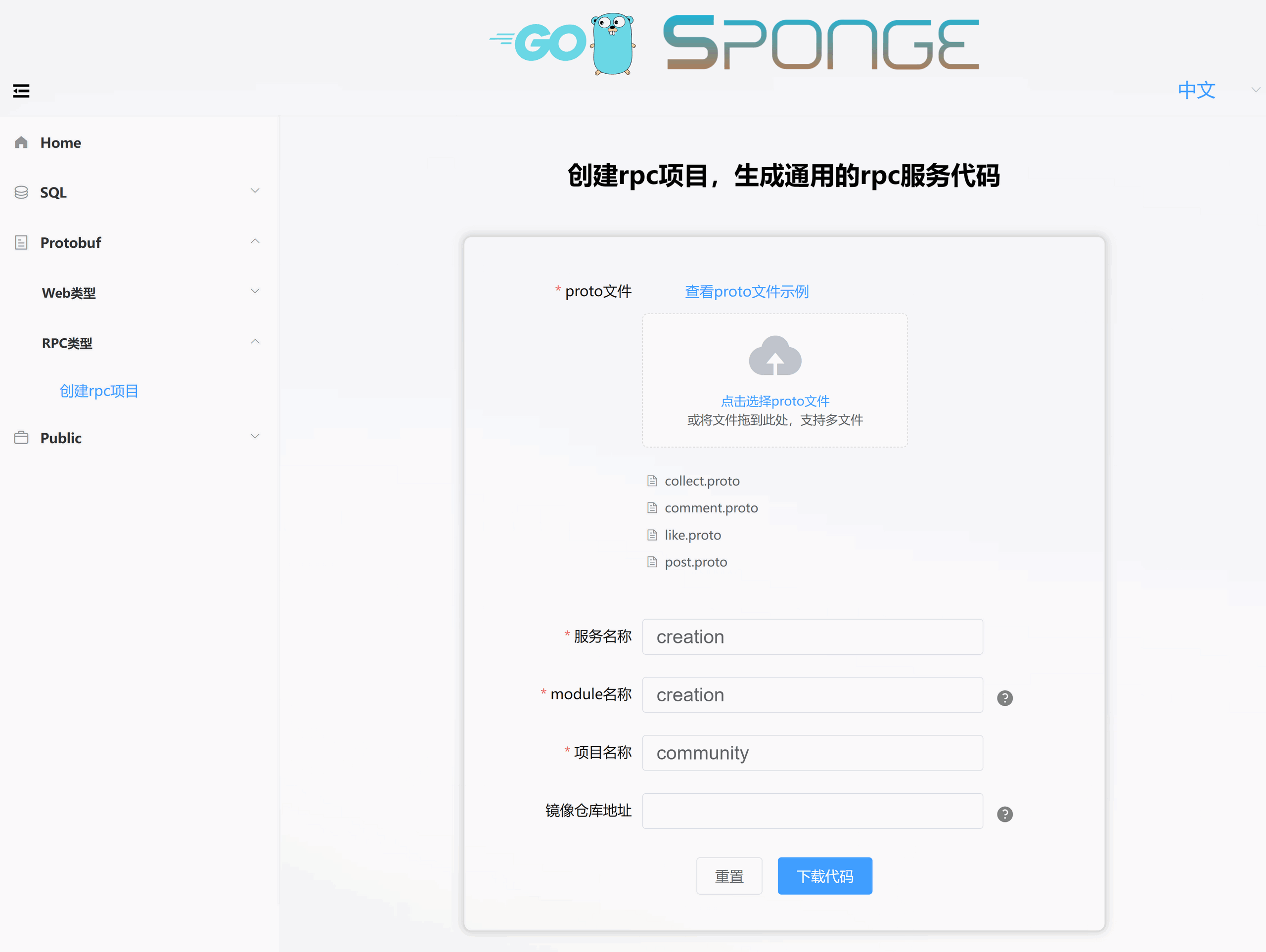
解压代码,把目录名称改为creation,然后把creation目录移动community-cluster目录下。
经过简单的界面操作就创建了三个gRPC服务(user、relation、creation),也就是完成了各个gRPC服务各自的图1中蛋壳部分,接下来完成图1中蛋白和蛋黄两部分代码。
编写user、relation、creation服务的业务逻辑代码
从上面图1中微服务鸡蛋模型解剖图看出,经过sponge剥离后的业务逻辑代码只包括蛋白和蛋黄两部分,编写业务逻辑代码都是围绕这两部分开展。
编写user服务业务逻辑代码
分三个步骤编写user服务业务逻辑代码。
第一步 生成模板代码,进入项目user目录,打开终端,执行命令:
make proto
这个命令生成了api接口模板代码、api接口错误码、rpc客户端测试代码和pb.go相关代码,这些代码对应图1中蛋白部分。
- api接口模板代码,在
internal/service目录下,文件名称与proto文件名一致,后缀名是_login.go,文件里面的方法函数与proto文件定义的rpc方法名一一对应,默认每个方法函数下有简单的使用示例,只需在每个方法函数里面编写具体的逻辑代码。 - api接口错误码,在
internal/ecode目录下,文件名称与proto文件名一致,后缀是_rpc.go,文件里面的默认错误码变量与proto文件定义的rpc方法名一一对应,在这里添加或更改业务相关的错误码,注意错误码不能重复,否则会触发panic。 - rpc客户端测试代码,在
internal/service目录下,文件名称与proto文件名一致,后缀是_client_test.go,文件里面的方法函数与proto文件定义的rpc方法名一一对应,填写参数,就可以每个rpc方法。
第二步 迁移dao代码,把单体web服务community-single目录中的internal/model、internal/cache、internal/dao、,internal/ecode这四个目录下user开头的代码文件,复制到user服务目录下,复制后的目录和文件名称不变。复制的这些代码对应图1中蛋白部分。
第三步 迁移具体逻辑代码,把单体web服务community-single代码文件internal/handler/user_logic.go各个方法函数下的具体逻辑代码,复制到user服务代码文件internal/service/user_logic.go同名的函数下。这些代码是图1中蛋黄的编写业务逻辑代码部分。
编写relation服务业务逻辑代码
分三个步骤编写relation服务业务逻辑代码,参考上面user服务的三个步骤。
编写creation服务业务逻辑代码
分三个步骤编写creation服务业务逻辑代码,参考上面user服务的三个步骤。
测试user、relation、creation服务的rpc方法
测试user服务的rpc方法
编写了业务逻辑代码后,启动服务来测试rpc方法,在第一次启动服务前,先打开配置文件(user/configs/user.yml)设置mysql和redis地址、设置grpc和grpcClient相关参数,然后执行命令编译启动服务:
# 编译、运行服务
make run
在goland IDE打开user服务代码,进入user/internal/service目录,找到后缀为_client_test.go的代码文件,在各个rpc方法填写参数后进行测试。
测试relation服务的rpc方法
测试relation服务的rpc方法,请参考上面user服务的测试rpc方法。
测试creation服务的rpc方法
测试creation服务的rpc方法,请参考上面user服务的测试rpc方法。
rpc网关服务
完成了user、relation、creation这三个服务后,接着需要完成rpc网关服务community_gw,community_gw作为user、relation、creation服务的统一入口。
创建community_gw服务
进入sponge的UI界面,点击左边菜单栏【Protobuf】–> 【Web类型】–>【创建rpc网关项目】,填写一些参数生成rpc网关服务代码。
这是从单体服务community-single复制过来的proto文件user_gw.proto、relation_gw.proto、post_gw.proto、comment_gw.proto、like_gw.proto、collect_gw.proto,快速创建rpc网关服务community_gw,如下图所示:
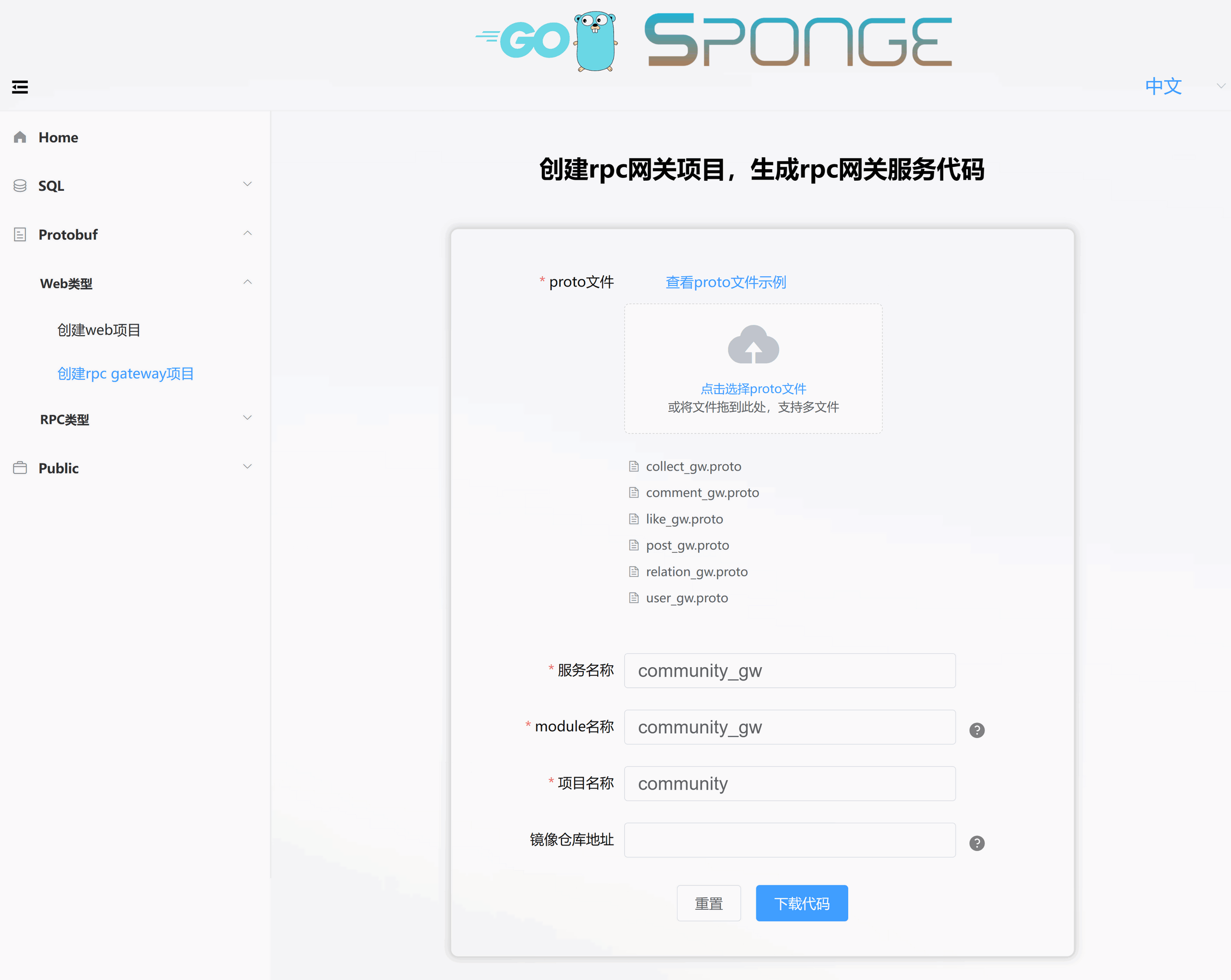
解压代码,把目录名称改为community_gw。
因为community_gw服务作为请求入口,使用rpc方式与user、relation、creation通信,因此需要生成连接user、relation、creation服务的代码。进入sponge的UI界面,点击左边菜单栏【Public】–>【生成rpc服务连接代码】,填写一些参数生成rpc服务连接代码,如下图所示:
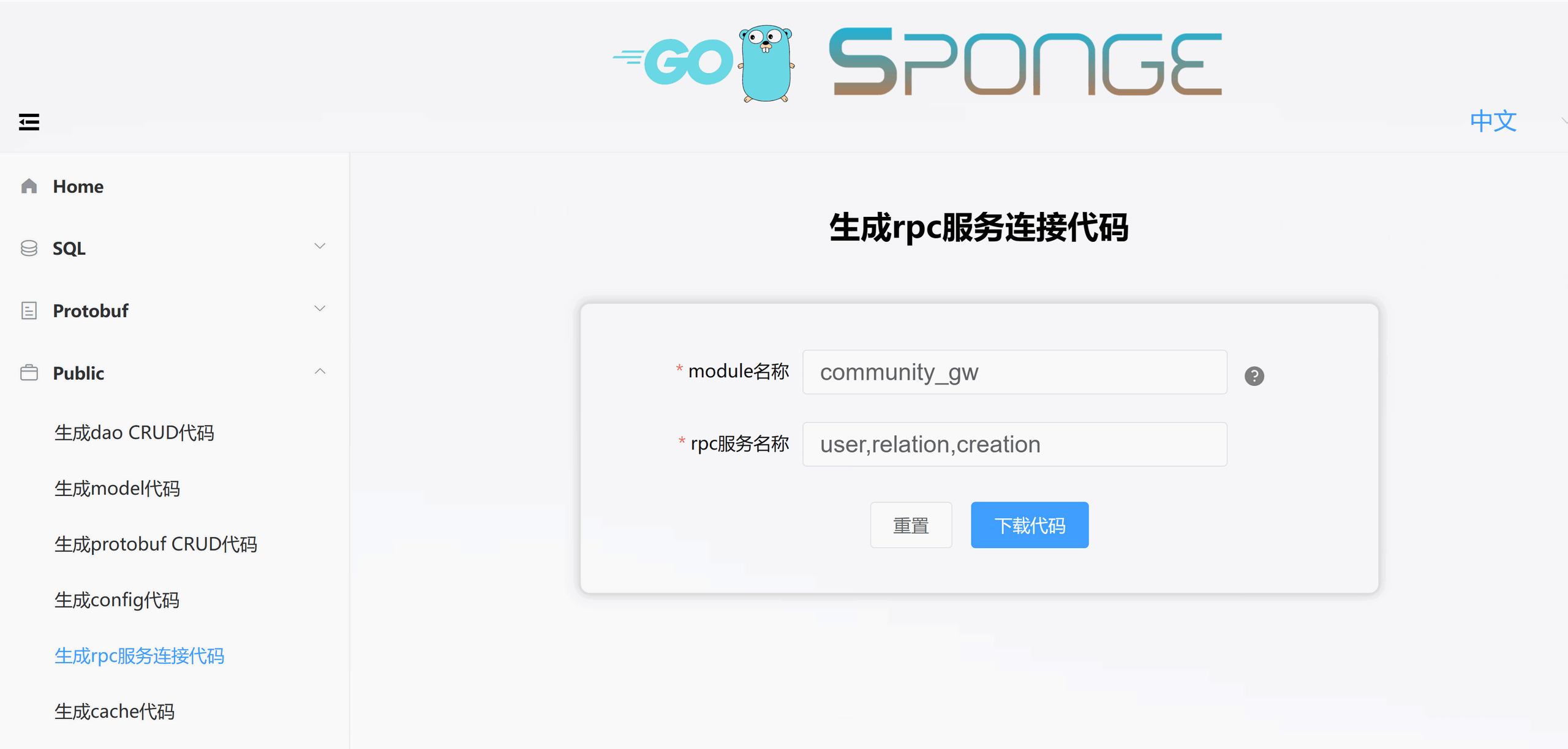
解压代码,把目录internal移动到community_gw服务目录下,然后把community_gw移动到community_cluster目录下。
同时把user、relation、creation三个服务的proto文件复制到community_gw的api目录下,如下列表所示。其中community_gw的v1目录下的proto文件是定义http的api接口信息,建议统一约定后缀名_gw.proto。
.
├── community_gw
│ └── v1
│ ├── collect_gw.proto
│ ├── comment_gw.proto
│ ├── like_gw.proto
│ ├── post_gw.proto
│ ├── relation_gw.proto
│ └── user_gw.proto
├── creation
│ └── v1
│ ├── collect.proto
│ ├── comment.proto
│ ├── like.proto
│ └── post.proto
├── relation
│ └── v1
│ └── relation.proto
└── user
└── v1
└── user.proto
通过简单的操作就完成创建了rpc网关服务community_gw。
编写community_gw服务的业务逻辑代码
从上面图2中rpc网关代码鸡蛋模型解剖图看出,经过sponge剥离后的业务逻辑代码只包括蛋白和蛋黄两部分,编写业务逻辑代码都是围绕这两部分开展。
编写与proto文件相关的业务逻辑代码
进入项目community-gw目录,打开终端,执行命令:
make proto
这个命令是根据community_gw/api/community_gw/v1目录下的proto文件生成了api接口模板代码、注册路由代码、api接口错误码、swagger文档和相关的pb.go代码,也就是图2中的蛋白部分。
(1) api接口模板代码,在community_gw/internal/service目录下,文件名称与proto文件名一致,后缀名是_logic.go,名称分别有:
collect_gw_logic.go, comment_gw_logic.go, like_gw_logic.go, post_gw_logic.go, relation_gw_logic.go, user_gw_logic.go
在这些文件里面的方法函数与proto文件定义的rpc方法名一一对应,每个方法函数下有默认的使用示例,只需要简单调整就可以调用user、relation、creation服务端的rpc方法。上面那些文件代码是已经编写具体逻辑之后的代码。
(2) 注册路由代码,在community_gw/internal/routers目录下,文件名称与proto文件名一致,后缀名是_router.go,名称分别有:
collect_gw_router.go, comment_gw_router.go, like_gw_router.go, post_gw_router.go, relation_gw_router.go, user_gw_router.go
在这些文件里面的设置api接口的中间件,例如jwt鉴权,每个接口都已经存在中间件模板代码,只需要取消注释代码就可以使中间件生效,只需要取消注释代码就可以使中间件生效,支持路由分组和单独路由来设置gin中间件。
(3) api接口错误码,在community_gw/internal/ecode目录下,文件名称与proto文件名一致,后缀是_rpc.go,名称分别有:
collect_gw_rpc.go, comment_gw_rpc.go, like_gw_rpc.go, post_gw_rpc.go, relation_gw_rpc.go, user_gw_rpc.go
在这些文件里面的默认错误码变量与proto文件定义的rpc方法名一一对应,在这里添加或更改业务相关的错误码,注意错误码不能重复,否则会触发panic。
注: 如果调用的rpc方法本身包含了错误码,可以直接返回该错误码。
(4) swagger文档,在community_gw/docs目录下,名称为apis.swagger.json
如果在proto文件添加或更改了api接口,都需要再执行一次命令make proto即可,会自动把新生成代码自动合并到对应文件代码中,不用担心合并代码中会丢失已编写的业务逻辑代码问题,可以在/tmp/sponge_merge_backup_code目录下可以找到合并前的代码备份。
make proto命令生成的代码是用来连接web框架代码和业务逻辑核心代码的桥梁,也就是图2中的蛋白部分,通过分层生成代码的好处是减少编写代码。
测试api接口
编写了业务逻辑代码后,启动服务测试api接口,在第一次启动服务前,先打开配置文件(community_gw/configs/community_gw.yml)设置连接rpc服务配置信息,如下所示:
# grpc client settings, support for setting up multiple rpc clients
grpcClient:
- name: "user"
host: "127.0.0.1"
port: 18282
registryDiscoveryType: ""
enableLoadBalance: false
- name: "relation"
host: "127.0.0.1"
port: 28282
registryDiscoveryType: ""
enableLoadBalance: false
- name: "creation"
host: "127.0.0.1"
port: 38282
registryDiscoveryType: ""
enableLoadBalance: false
执行命令编译启动服务:
# 编译、运行服务
make run
在浏览器访问 http://localhost:8080/apis/swagger/index.htm ,进入swagger界面,如下图所示:
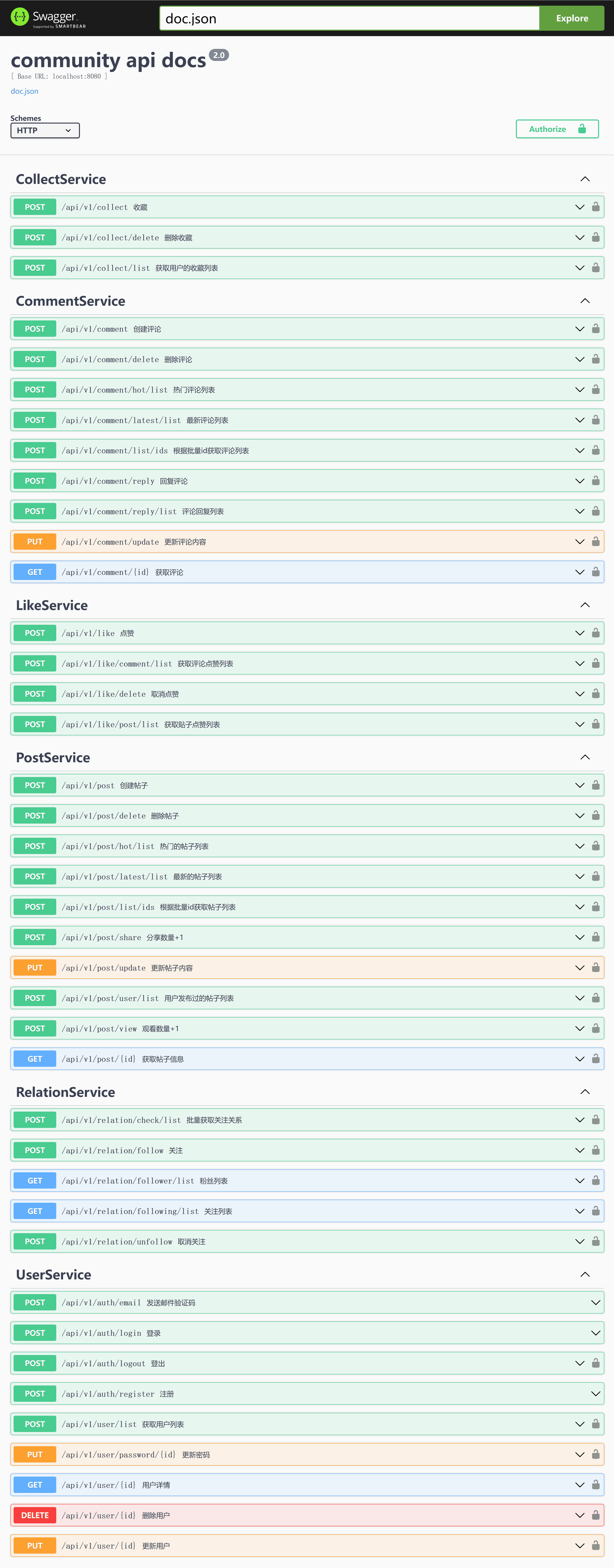
从图中看到有些api接口右边有一把锁标记,表示请求头会携带鉴权信息Authorization,服务端接收到请求是否做鉴权,由服务端决定,如果服务端需要做鉴权,可以在community_gw/internal/routers目录下后缀文件为_router.go文件中设置,也就是取消鉴权的注释代码,使api接口的鉴权中间件生效。
服务治理
gRPC服务(user、relation、creation)和rpc网关服务(community-gw)都包含了丰富的服务治理插件(日志、限流、熔断、链路跟踪、服务注册与发现、指标采集、性能分析、资源统计、配置中心),有些服务治理插件默认是关闭的,根据实际需要开启使用。
除了服务本身提供的治理插件,也可以使用自己的服务治理插件,添加自己的服务治理插件说明:
- 对于gRPC服务(user、relation、creation),在代码文件
服务名称/internal/server/grpc.go里添加自己的插件,如果你的服务治理插件(拦截器)属于unary类型,添加到unaryServerOptions函数里面。如果你的服务治理插件(拦截器)属于stream类型,添加到streamServerOptions函数里面。 - 对于rpc网关服务community-gw,在代码文件
community-gw/internal/routers/routers.go里添加自己的插件(gin中间件)。
下面是默认的服务治理插件开启和设置说明,统一在各自服务配置文件服务名称/configs/服务名称.yml进行设置。
日志
日志插件(zap)默认是开启的,默认是输出到终端,默认输出日志格式是console,可以设置输出格式为json,设置日志保存到指定文件,日志文件切割和保留时间。
在配置文件里的字段logger设置:
# logger 设置
logger:
level: "info" # 输出日志级别 debug, info, warn, error,默认是debug
format: "console" # 输出格式,console或json,默认是console
isSave: false # false:输出到终端,true:输出到文件,默认是false
logFileConfig: # isSave=true时有效
filename: "out.log" # 文件名称,默认值out.log
maxSize: 20 # 最大文件大小(MB),默认值10MB
maxBackups: 50 # 保留旧文件的最大个数,默认值100个
maxAge: 15 # 保留旧文件的最大天数,默认值30天
isCompression: true # 是否压缩/归档旧文件,默认值false
限流
限流插件默认是关闭的,自适应限流,不需要设置其他参数。
在配置文件里的字段enableLimit设置:
enableLimit: false # 是否开启限流(自适应),true:开启, false:关闭
熔断
熔断插件默认是关闭的,自适应熔断,支持自定义错误码(默认500和503)触发熔断,在internal/routers/routers.go设置。
在配置文件里的字段enableCircuitBreaker设置:
enableCircuitBreaker: false # 是否开启熔断(自适应),true:开启, false:关闭
链路跟踪
链路跟踪插件默认是关闭的,链路跟踪依赖jaeger服务。
在配置文件里的字段enableTrace设置:
enableTrace: false # 是否开启追踪,true:启用,false:关闭,如果是true,必须设置jaeger配置。
tracingSamplingRate: 1.0 # 链路跟踪采样率, 范围0~1.0浮点数, 0表示不采样, 1.0表示采样所有链路
# jaeger 设置
jaeger:
agentHost: "192.168.3.37"
agentPort: 6831
在jaeger界面上查看链路跟踪信息文档说明。
服务注册与发现
服务注册与发现插件默认是关闭的,支持consul、etcd、nacos三种类型。
在配置文件里的字段registryDiscoveryType设置:
registryDiscoveryType: "" # 注册和发现类型:consul、etcd、nacos,如果为空表示关闭服务注册与发现。
# 根据字段registryDiscoveryType值来设置参数,例如使用consul作为服务发现,只需设置consul。
# consul 设置
consul:
addr: "192.168.3.37:8500"
# etcd 设置
etcd:
addrs: ["192.168.3.37:2379"]
# nacos 设置
nacosRd:
ipAddr: "192.168.3.37"
port: 8848
namespaceID: "3454d2b5-2455-4d0e-bf6d-e033b086bb4c" # namespace id
指标采集
指标采集功能默认是开启的,提供给prometheus采集数据,默认路由是/metrics。
在配置文件里的字段enableMetrics设置:
enableMetrics: true # 是否开启指标采集,true:启用,false:关闭
使用prometheus和grafana采集指标和监控服务的文档说明。
性能分析
性能分析插件默认是关闭的,采集profile的默认路由是/debug/pprof,除了支持go语言本身提供默认的profile分析,还支持io分析,路由是/debug/pprof/profile-io。
在配置文件里的字段enableHTTPProfile设置:
enableHTTPProfile: false # 是否开启性能分析,true:启用,false:关闭
通过路由采集profile进行性能分析方式,通常在开发或测试时使用,如果线上开启会有一点点性能损耗,因为程序后台一直定时记录profile相关信息。sponge生成的服务本身对此做了一些改进,平时停止采集profile,用户主动触发系统信号时才开启和关闭采集profile,采集profile保存到/tmp/服务名称_profile目录,默认采集为60秒,60秒后自动停止采集profile,如果只想采集30秒,发送第一次信号开始采集,大概30秒后发送第二次信号表示停止采集profile,类似开关一样。
这是采集profile操作步骤:
# 通过名称查看服务pid
ps aux | grep 服务名称
# 发送信号给服务
kill -trap pid值
注:只支持linux、darwin系统。
资源统计
资源统计插件默认是开启的,默认每分钟统计一次并输出到日志,资源统计了包括系统和服务本身这两部分的cpu和内存相关的数据。
资源统计还包含了自动触发采集profile功能,当连续3次统计本服务的CPU或内存平均值,CPU或内存平均值占用系统资源超过80%时,自动触发采集profile,默认采集为60秒,采集profile保存到/tmp/服务名称_profile目录,从而实现了自适应采集profile,比通过人工发送系统信号来采集profile又改进了一步。
在配置文件里的字段enableHTTPProfile设置:
enableStat: true # 是否开启资源统计,true:启用,false:关闭
配置中心
目前支持nacos作为配置中心,配置中心文件configs/user_cc.yml,配置内容如下:
# nacos 设置
nacos:
ipAddr: "192.168.3.37" # 服务地址
port: 8848 # 监听端口
scheme: "http" # 支持http和https
contextPath: "/nacos" # 路径
namespaceID: "3454d2b5-2455-4d0e-bf6d-e033b086bb4c" # namespace id
group: "dev" # 组名称: dev, prod, test
dataID: "community.yml" # 配置文件id
format: "yaml" # 配置文件类型: json,yaml,toml
而服务的配置文件configs/user.yml复制到nacos界面上配置。使用nacos配置中心,启动服务命令需要指定配置中心文件,命令如下:
./user -c configs/user_cc.yml -enable-cc
使用nacos作为配置中心的文档说明。
持续集成与部署
sponge生成的gRPC和rpc网关服务包括了编译和部署脚本,编译支持二进制编译和docker镜像构建,部署支持二进制部署、docker部署、k8s部署三种方式,这些功能都统一集成在Makefile文件里,使用make命令就可以很方便的执行指定编译或部署服务。
除了使用make命令编译和部署,还支持自动化部署工具Jenkins,默认的Jenkins设置在文件Jenkinsfile,支持自动化部署到k8s,如果需要二进制或docker部署,需要对Jenkinsfile进行修改。
使用Jenkins持续集成和部署的文档说明。
服务压测
压测服务时使用的一些工具:
- http压测工具wrk或go-stress-testing。
- 服务开启指标采集功能,使用prometheus采集服务指标和系统指标进行监控。
- 服务本身的自适应采集profile功能。
压测指标:
- 并发度: 逐渐增加并发用户数,找到服务的最大并发度,确定服务能支持的最大用户量。
- 响应时间: 关注并发用户数增加时,服务的平均响应时间和响应时间分布情况。确保即使在高并发下,响应时间也在可接受范围内。
- 错误率: 观察并发增加时,服务出现错误或异常的概率。使用压测工具进行长时间并发测试,统计各并发级别下的错误数量和类型。
- 吞吐量: 找到服务的最大吞吐量,确定服务在高并发下可以支持的最大请求量。这需要不断增加并发,直到找到吞吐量饱和点。
- 资源利用率: 关注并发增加时,CPU、内存、磁盘I/O、网络等资源的利用率,找到服务的资源瓶颈。
- 瓶颈检测: 通过观察高并发情况下服务的性能指标和资源利用率,找到系统和服务的硬件或软件瓶颈,以便进行优化。
- 稳定性: 长时间高并发运行可以检测到服务存在的潜在问题,如内存泄露、连接泄露等,确保服务稳定运行。这需要较长时间的并发压测,观察服务运行指标。
对服务进行压测,主要是为了评估其性能,确定能支持的最大并发和吞吐量,发现当前的瓶颈,并检测服务运行的稳定性,以便进行优化或容量规划。
总结
本文介绍了把单体服务community-single拆分为微服务集群community-cluster的具体实践过程,微服务集群包括了用户服务(user)、关系服务(relation)和内容创作服务(creation)三个独立的服务,一个微服务入口的网关服务(community_gw),这些服务代码(图1和图2中的蛋壳和蛋白部分)都是由工具sponge生成,核心业务逻辑代码是直接手动无缝移植,基本不需要重复编写代码,减少了大量工作量,从而提高了效率。
如果不是从单体服务拆分为微服务,而是项目一开始采用微服务集群,使用sponge开发的步骤也是一样,一开始采用微服务集群时,核心业务逻辑代码(图1和图2中的蛋黄部分)需要人工编写。
使用工具sponge从开发到部署gRPC服务具体流程如下:
- 定义mysql表
- 在proto文件定义api接口
- 生成gRPC服务框架代码
- 根据proto文件生成业务逻辑相关代码
- 根据mysql表生成dao代码
- 在api接口模板文件中编写具体逻辑代码
- 在生成的rpc客户端代码中测试验证api接口
- 按需启用服务治理功能
- 持续集成与部署
- 服务压测
开发一个完整的gRPC服务,真正需要人工编写代码的只有1、2、6这三个核心业务代码。
使用工具sponge从开发到部署rpc网关服务具体流程如下:
- 在proto文件定义api接口
- 生成rpc网关服务框架代码
- 生成prc服务连接代码
- 根据proto文件生成业务逻辑相关代码
- 在api接口模板文件中编写具体逻辑代码
- 在swagger页面测试验证api接口
- 按需启用服务治理功能
- 持续集成与部署
- 服务压测
开发一个完整的rpc网关服务,真正需要人工编写代码的只有1、5这两个核心业务代码。
使用工具sponge很容易开发一个完整的微服务集群,微服务集群的优点:
- 高性能:基于 Protobuf 的高性能通信协议,同时具备高并发处理和低延迟的特点。
- 可扩展性:丰富的插件和组件机制,开发者可以根据实际需求定制和扩展框架功能。
- 高可靠性:提供了服务注册和发现、限流、熔断、链路、监控告警等功能,提升了微服务的可靠性。
专题「golang相关」的其它文章 »
- DeepSeek与Sponge黄金组合打造后端高效开发新范式 (Feb 09, 2025)
- 使用开发框架sponge一天多开发完成一个简单版社区后端服务 (Jul 30, 2023)
- 一个强大的Go开发框架sponge,以低代码方式开发项目 (Jan 06, 2023)
- go test命令 (Apr 15, 2022)
- go应用程序性能分析 (Mar 29, 2022)
- channel原理和应用 (Mar 22, 2022)
- go runtime (Mar 14, 2022)
- go调试工具 (Mar 13, 2022)
- cobra基础与实践 (Mar 10, 2022)
- grpc基础与实践 (Nov 27, 2020)
- 配置文件viper库 (Nov 22, 2020)
- 根据服务名称查看golang程序的profile信息 (Sep 03, 2019)
- go语言开发规范 (Aug 28, 2019)
- goroutine和channel应用——处理队列 (Sep 06, 2018)
- golang中的context包 (Aug 28, 2018)