#runtime #GMP #goroutine
go语言组成有两部分,一部分是用户程序代码,一部分是runtime,runtime作用是为了实现额外功能,在程序运行时自动加载/运行的的一些模块,runtime由4部分组成:
- Scheduler: 调度器管理所有的GMP,在后台执行调度循环。
- Memory Management: 当代码需要内存时,负责内存分配工作。
- Garbage Collector: 当内存不再需要时,负责回收内存。
- Netpoll: 网络轮询负责管理网络FD相关的读写、就绪事件。
调度器 Scheduler
协程调度器GMP
调度器本质是一个生产-消费流程,用户在程序中执行go func{}生成一个协程实体,提交到协程调度器,线程来执行(消费)。
- G: goroutine,一个计算任务。由需要执行的代码和其上下文组成,上下文包括:当前代码位置,栈顶、栈底地址,状态等。
- M: machine,系统线程,执行实体,想要在CPU上执行代码,必须有线程,与C语⾔中的线程相同,通过系统调⽤clone来创建。
- P: processor,虚拟处理器,M必须获得P才能执行代码,否则必须陷入休眠(后台监控线程除外),你也可以将其理解为⼀种token ,有这个token,才有在物理CPU核心上执行的权力。
协程框架图
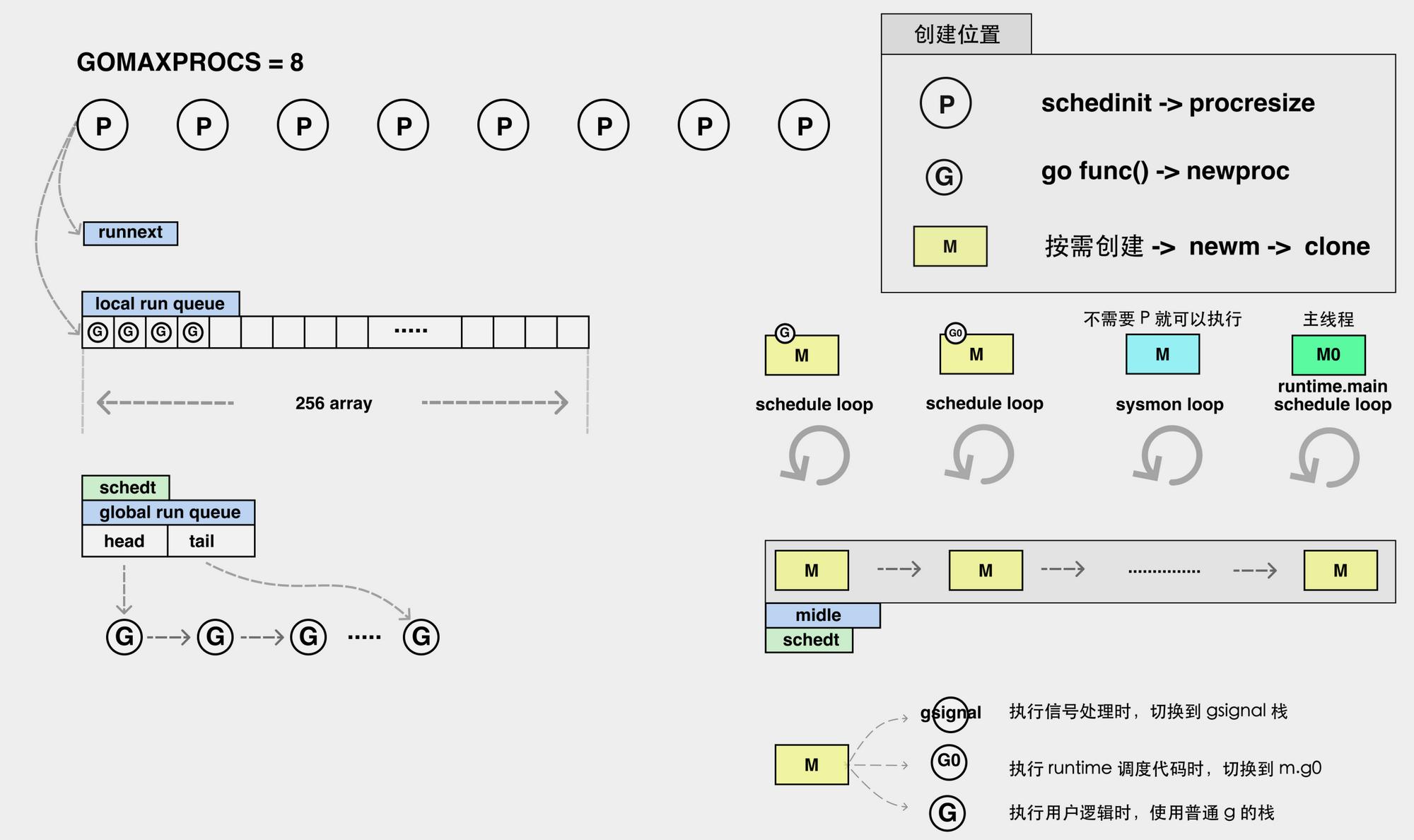
上图左边是表示协程生产过程,包括虚拟处理器部分P和队列部分,每个P下面有runnext和local run quene,而global run quene是全局链表,所有P都可以共享,G执行优先级别最高是runnext,其次是本地队列,最后是全局队列。
- runnext: 下一个执行的G,类型是一个值。
- local run quene:每个P自己队列,类型是数组,最大长度为256。
- global run quene,全局队列,类型是链表,长度没有限制。
为什么队列要分为本地队列和全局队列?
为了在性能上达到更好目标,每个P执行自己的本地队列,不需要枷锁,而不同P之间频繁从全局队列获取G时要加锁的,队列分级就是避免频繁加锁,提高并发性能。
为什么最新创建的协程会被放到runnext去优先执行?
在计算机执行过程中,程序分为代码的局部性和数据的局部性,根据局部性原理,最近调用的代码,很大概率需要再一次调用,优先级更高,程序执行到当前时刻,变量和数据很大概率在当前CPU访问的cache里,因此访问效率也是最高的。刚刚创建的G很大概率是高优先级的G,因此放到runnext去优先执行。
上图的右边是协程的消费端,包括系统线程部分,工作的线程绑定P后一直调度循环,线程是按需创建的,空闲的线程在队列里,需要时再拿出来。
协程生产端
新创建的协程加入队列的流程图
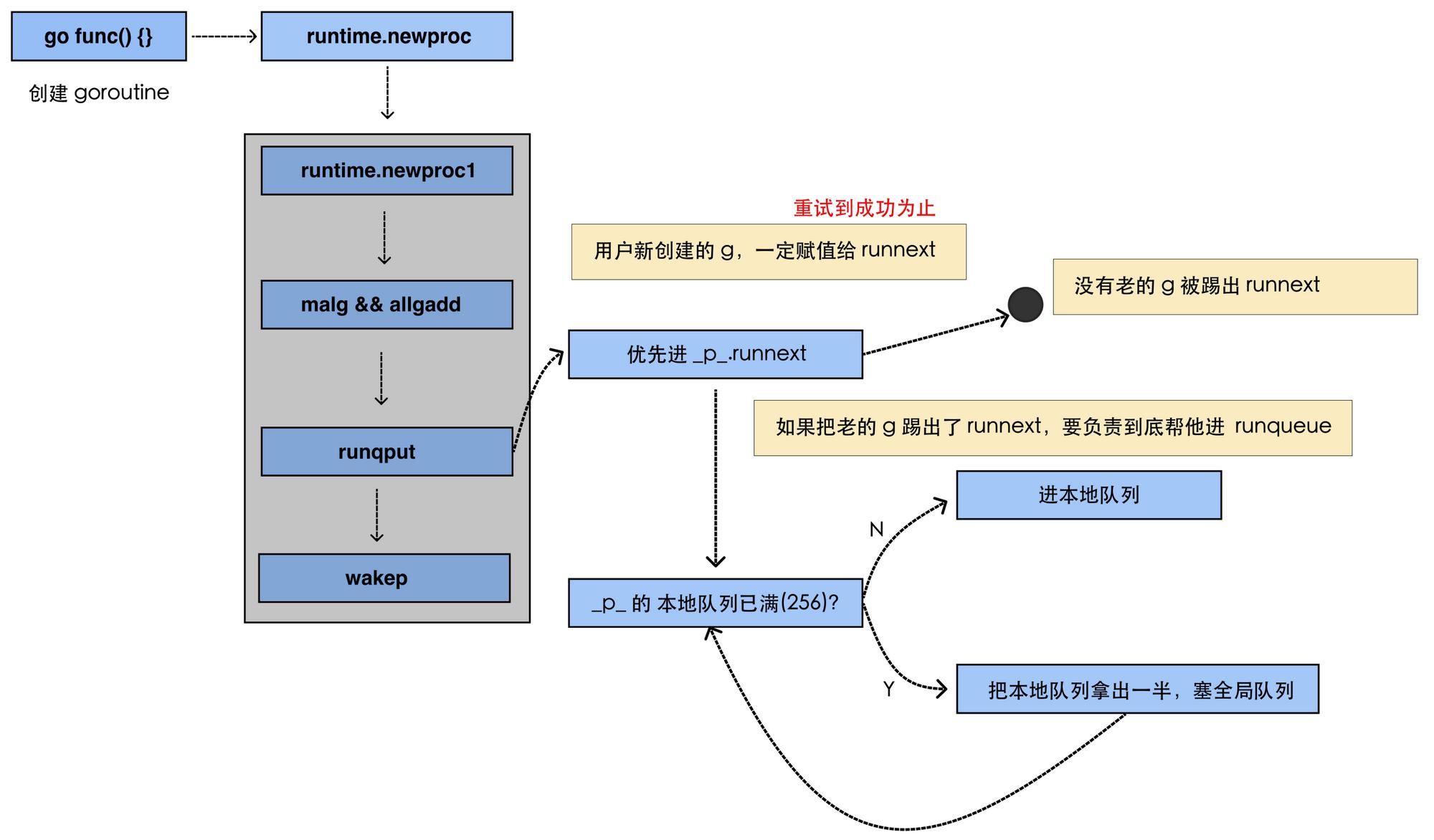
使用go func()函数,通过newproc打包生产一个G,newproc里面做了申请栈、判断当前runnext、本地队列、全局队列是否需要对已存在的G进行转移,有三种情况:
- 第一种情况:runnext为空,新创建的G直接放到runnext去执行。
- 第二种情况:runnext为不空,本地队列未满(最大256),把runnext旧的G转移到本地队列,新创建的G放到runnext去执行。
- 第三种情况:runnext为不空,本地队列已满(最大256),把runnext旧的G和和本地队列的一半G放到全局队列(全局队列时链表,理论是无限大),新创建的G放到runnext去执行。
协程消费端
协程消费端框架图
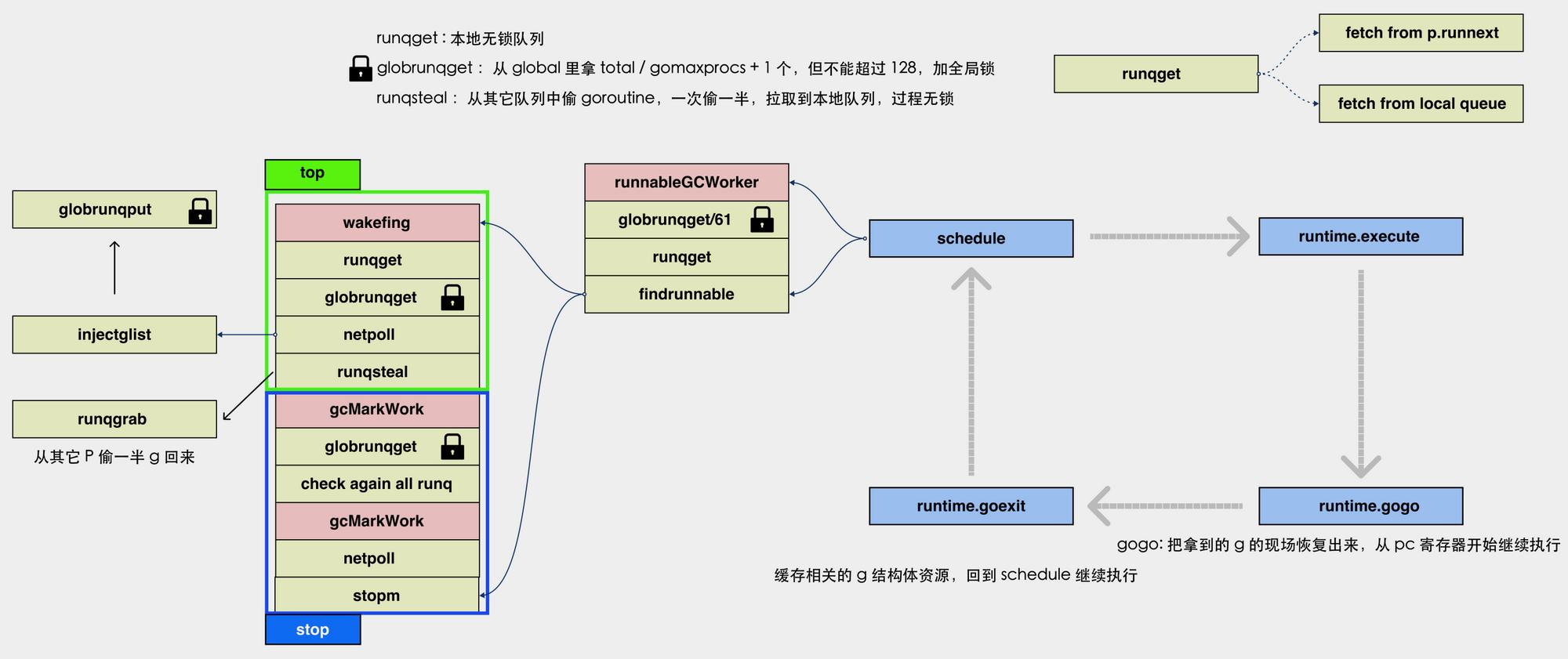
消费过程:
每循环调度一次schedtick值加1,每轮询60次本地队列,就去全局队列获取,目的是让全局队列的G也有机会被执行。
schedtick对60取模等于0的消费过程
全局队列不为空,本地队列不为空情况,从全局队列获取一个G来执行。
schedtick对60取模不为0的消费过程
- 当runnext有G,直接从runnext获取G执行。
- 当runnext为空,本地队列有G,从本地队列中获取G执行
- 当runnext为空,本地队列为空,全局队列有G,从全局队列获一批G来执行,从全局队列获取G数量规则是从全局队列获取一半,如果数量超过128,最大值取128,获取的是全局队列的尾部。
- 当runnext为空,本地队列为空,全局队列为空,查询其他线程的本地队列是否有G,如果其他P的本地队列有G,就从其他P的本地队列偷取一半(后半部分)到本地队列执行,如果其他P的本地队列也为空,则挣扎一下再查询一遍,如果全局和其他P都为空,然后进入休眠状态。
阻塞
上面的goroutine都是正常执行,当goroutine出现阻塞怎么处理呢。有些阻塞可以被runtime拦截,有些阻塞不能被runtime拦截。
runtime可以拦截的阻塞
常见会出现阻塞场景
(1) 调用time.Sleep函数
(2) 一直往channel写数据,另一端没来得及读取channel
(3) 一直读取channel数据,另一端没来得及写数据到channel
(4) 使用select,如果都没有出发channel,会阻塞
selct {
case <-c1:
fmt.Println("c1 read")
case <-c2:
fmt.Println("c2 read")
}
(5) 锁,当资源被锁了,还没释放,另一个goroutine获取不到锁,出现阻塞
(6) 网络读写
var conn net.Conn
var buf = make([]byte, 1024)
// 读,没数据时阻塞
conn.Read(buf)
// 写,缓冲满时阻塞
conn.Write(buf)
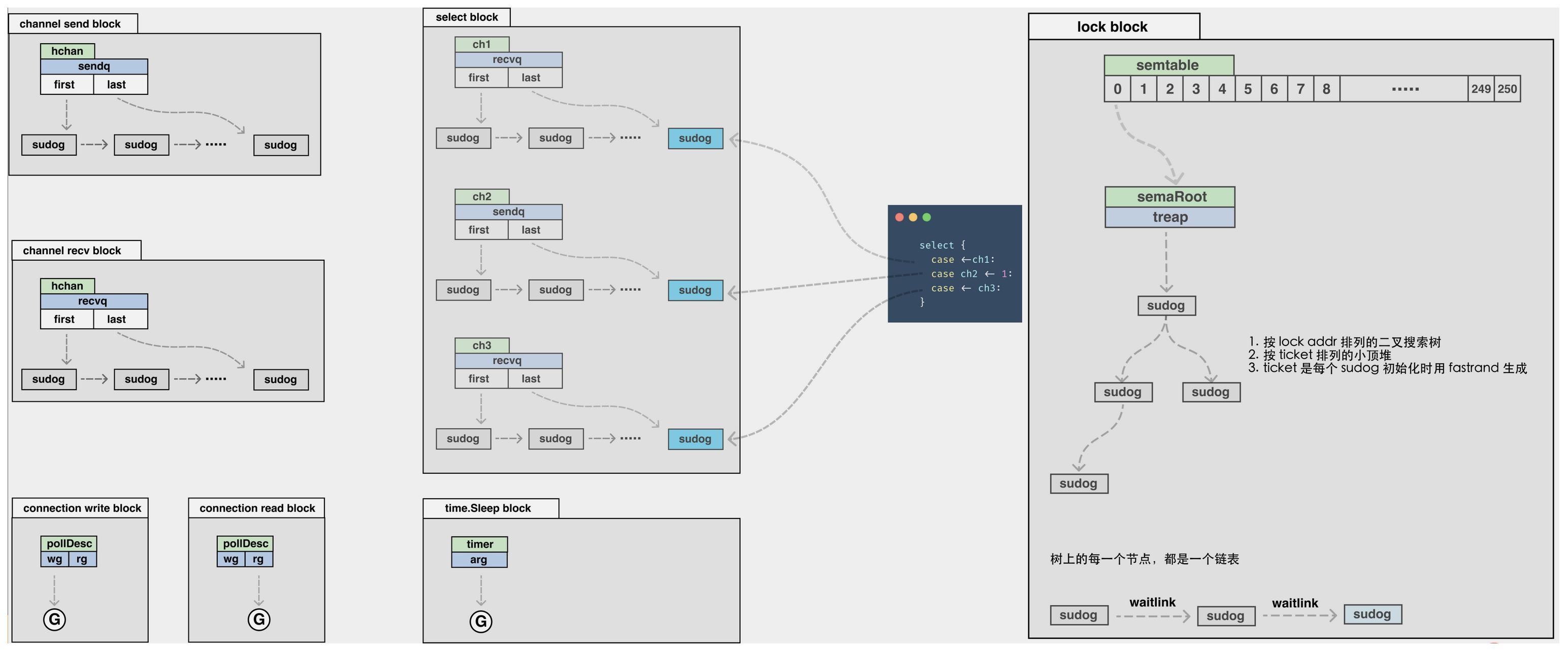
runtime 不能拦截的阻塞
有些阻塞runtime不能被捕获到,例如cgo、系统调用,执行c代码或系统调用时,如果长时间运行需要剥离P执行,单独占用⼀个线程。

阻塞处理
如果一个8核处理器的8个线程同时都执行系统调用,而且都阻塞了,怎么办?
需要一个专有线程sysmon(system monitor)专门处理这个问题,sysmon线程拥有优高先级,而且不需要绑定P就可以执行。
sysmon主要功能有三个:
- checkdead: 检查所有线程是否都已经被阻塞了,如果是,则抛出异常,如果只是网络服务,这个检测不起作用,因为accept是正常运行的,不要被字面意思误解为可以检查死锁。
- netpoll: 将g列表注入全局运行队列。
- retake: 如果是syscall卡了很久,那就把p剥离(handoffp),如果是用户g运行很久了(10ms),那么发信号SIGURG抢占。
内存管理 Memory Management
内存管理的三个角色
| 角色 | 说明 |
|---|---|
| Mutator | fancy(花哨的) word for application ,其实就是你写的应用程序,它会不断地修改对象的引用关系,即对象图。 |
| Allocator | 内存分配器,负责管理从操作系统中分配出的内存空间,malloc 其实底层就有⼀个内存分配器的实现(glibc中),tcmalloc是malloc多线程改进版。 Go中的实现类似tcmalloc 。 |
| Collector | 垃圾收集器,负责清理死对象,释放内存空间。 |
内存管理概览
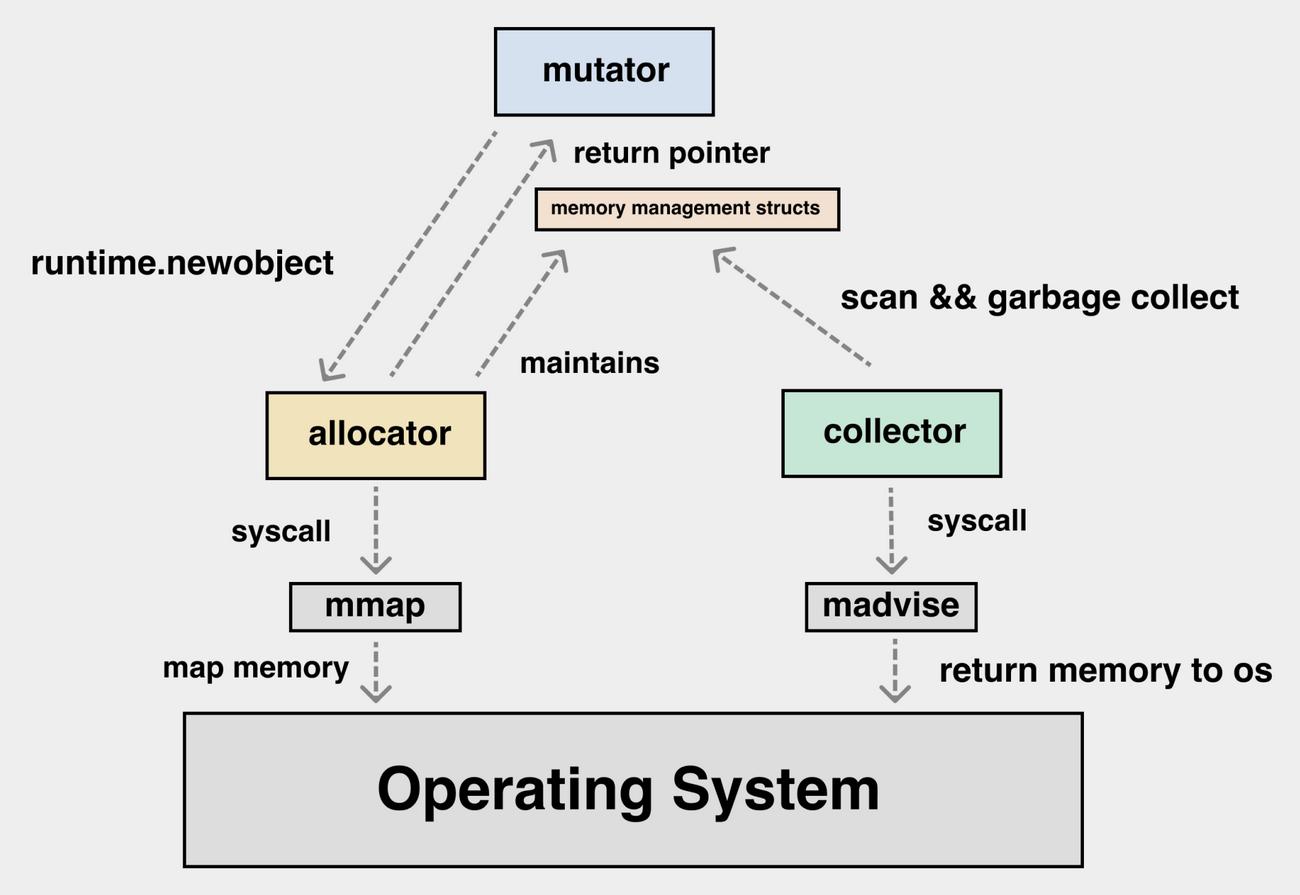
内存管理抽象
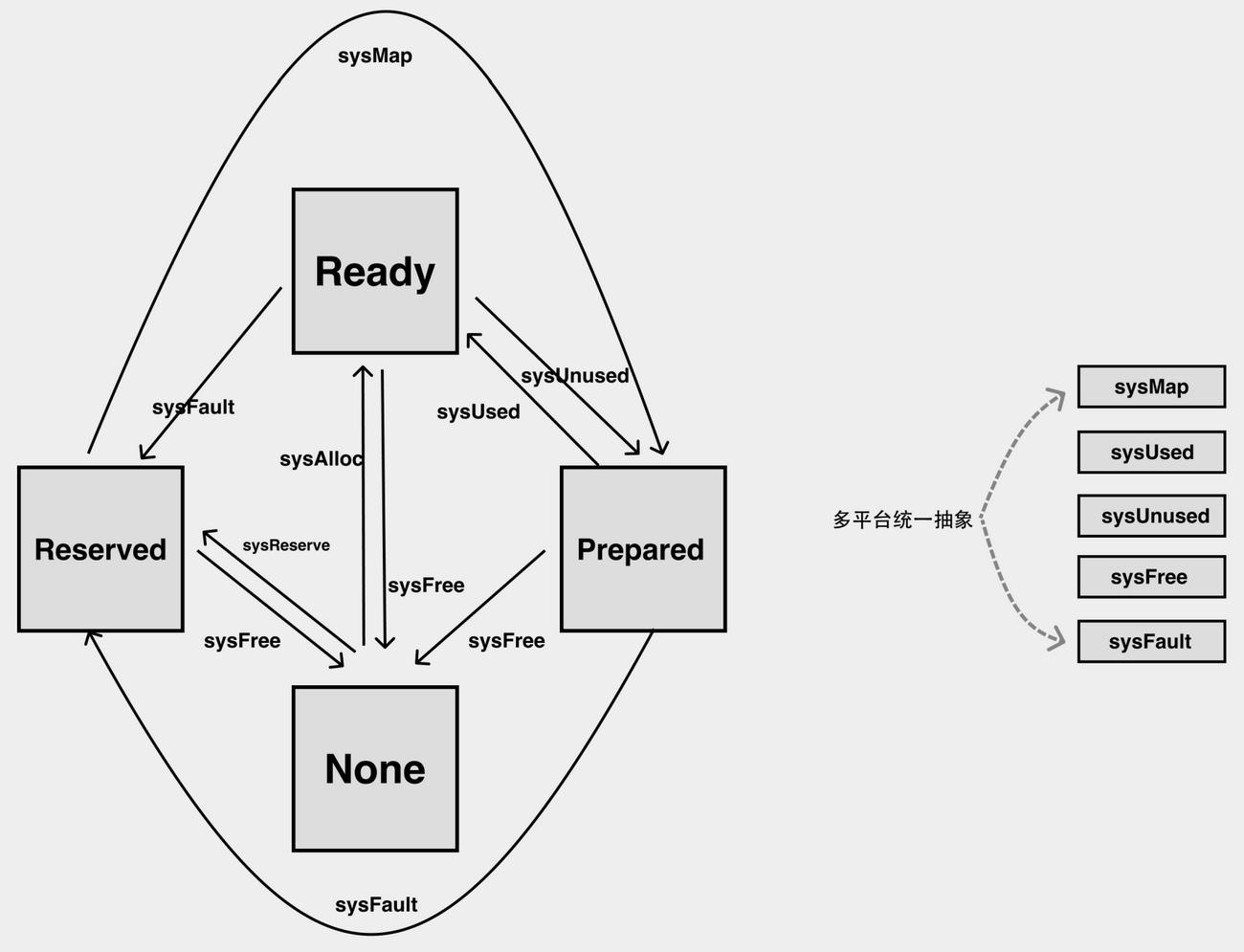
进程对应虚拟内存布局
内存分配器类型
(1) 线性分配器(Bump/Sequential Allocator)
Bump Sequential不会复用已经释放的内存,产生比较多内存碎片,基本不使用,Sequential Allocator可以复用已经释放内存,但是要额外维护一个free链表。
(2) 空闲链表分配器(Free List Allocator)
空闲链表分配器有first-fit、next-fit、best-fit、segregate-fit几种,go使用的是segregate-fit,减少内存碎片。
go语言内存分配
执行malloc时
- 分配内存小于128kb,brk只能通过调整 program break 位置推动堆增⻓
- 分配内存大于128kbmmap 可以从任意未分配位置映射内存
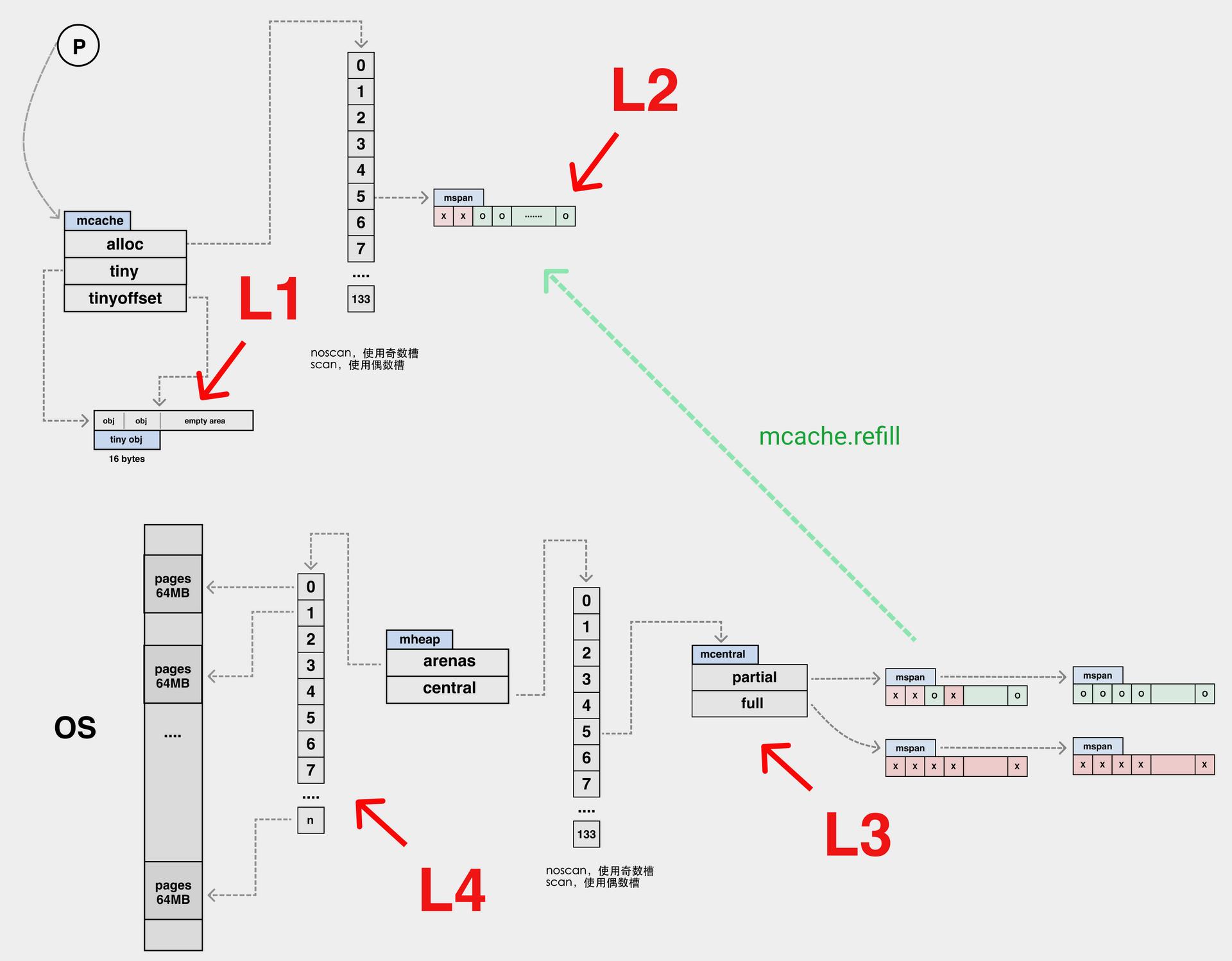
内存分配器在 Go 语⾔中维护了⼀个多级结构:mcache –> mcentral –> mheap
| 类型 | 说明 |
|---|---|
| mcache | 与P绑定,本地内存分配操作,不需要加锁。 |
| mcentral | 中⼼分配缓存,分配时需要上锁,不同spanClass使⽤不同的锁 |
| mheap | 全局唯⼀,从OS申请内存,并修改其内存定义结构时,需要加锁,是个全局锁。 |
go的内存分类,预先分配好内存。
// class bytes/obj bytes/span objects tail waste max waste min align
// 1 8 8192 1024 0 87.50% 8
// 2 16 8192 512 0 43.75% 16
// 3 24 8192 341 8 29.24% 8
// 4 32 8192 256 0 21.88% 32
// 5 48 8192 170 32 31.52% 16
// 6 64 8192 128 0 23.44% 64
// 7 80 8192 102 32 19.07% 16
// 8 96 8192 85 32 15.95% 32
...
// 66 28672 57344 2 0 4.91% 4096
// 67 32768 32768 1 0 12.50% 8192
堆内存管理有Tiny alloc、Small alloc、Large alloc几种方式
- Tiny alloc分配内存
- Small alloc分配内存
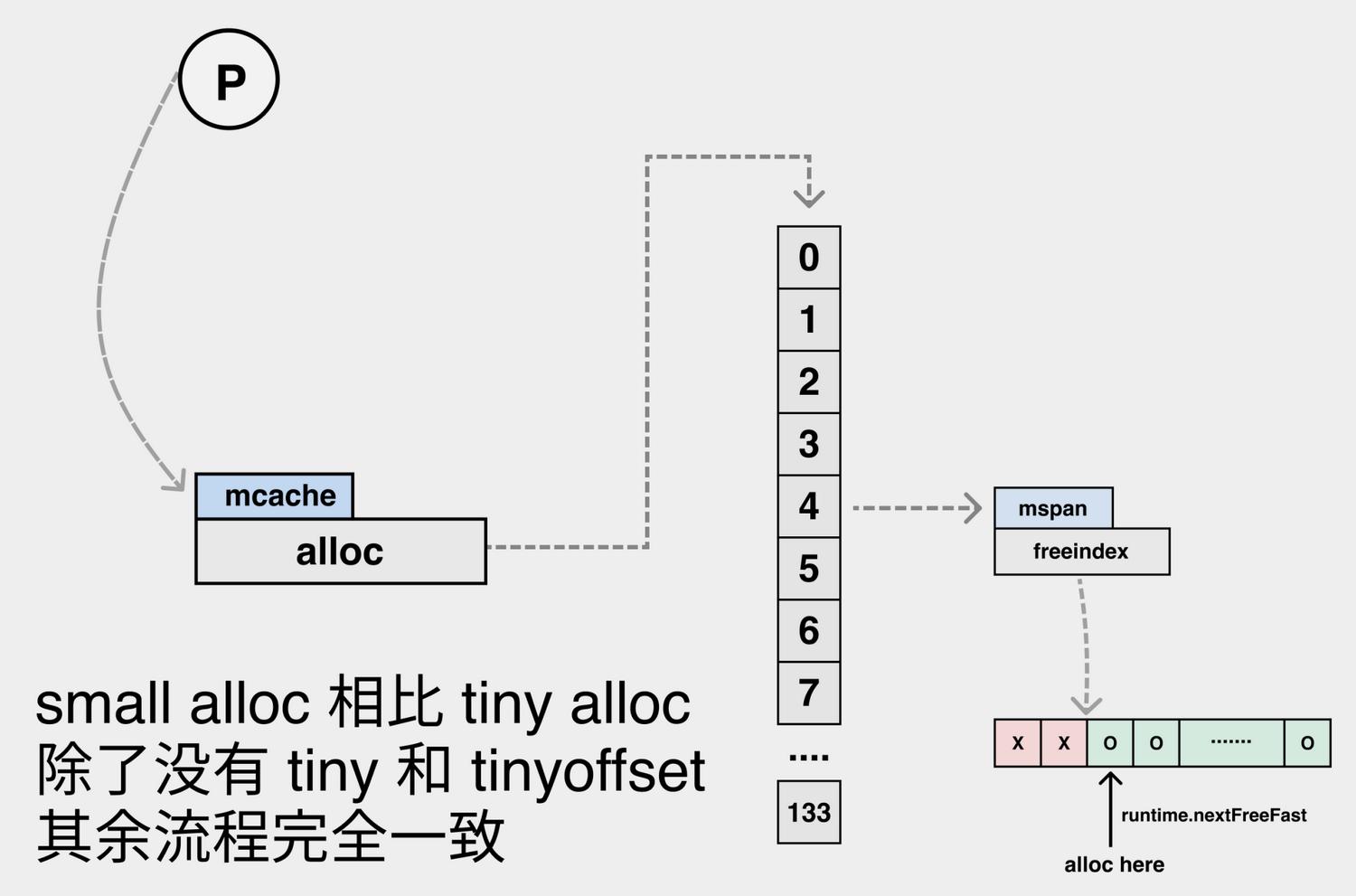
- Large alloc分配内存
⼤对象分配会直接越过mcache 、 mcentral ,直接从mheap进⾏相应数量的page分配,pageAlloc 结构经过多个版本的变化,从: freelist -> treap -> radix tree ,查找时间复杂度越来越低,结构越来越复杂。
Refill 流程:
- 本地 mcache 没有时触发 (mcache.refill)
- 从 mcentral ⾥的 non-empty 链表中找 (mcentral.cacheSpan)
- 尝试 sweep mcentral 的 empty , insert sweeped -> non-empty(mcentral.cacheSpan)
- 增⻓ mcentral ,尝试从 arena 获取内存 (mcentral.grow)
- arena 如果还是没有,向操作系统申请 (mheap.alloc)
最终还是会将申请到的mspan放在mcache中,如下图所示:
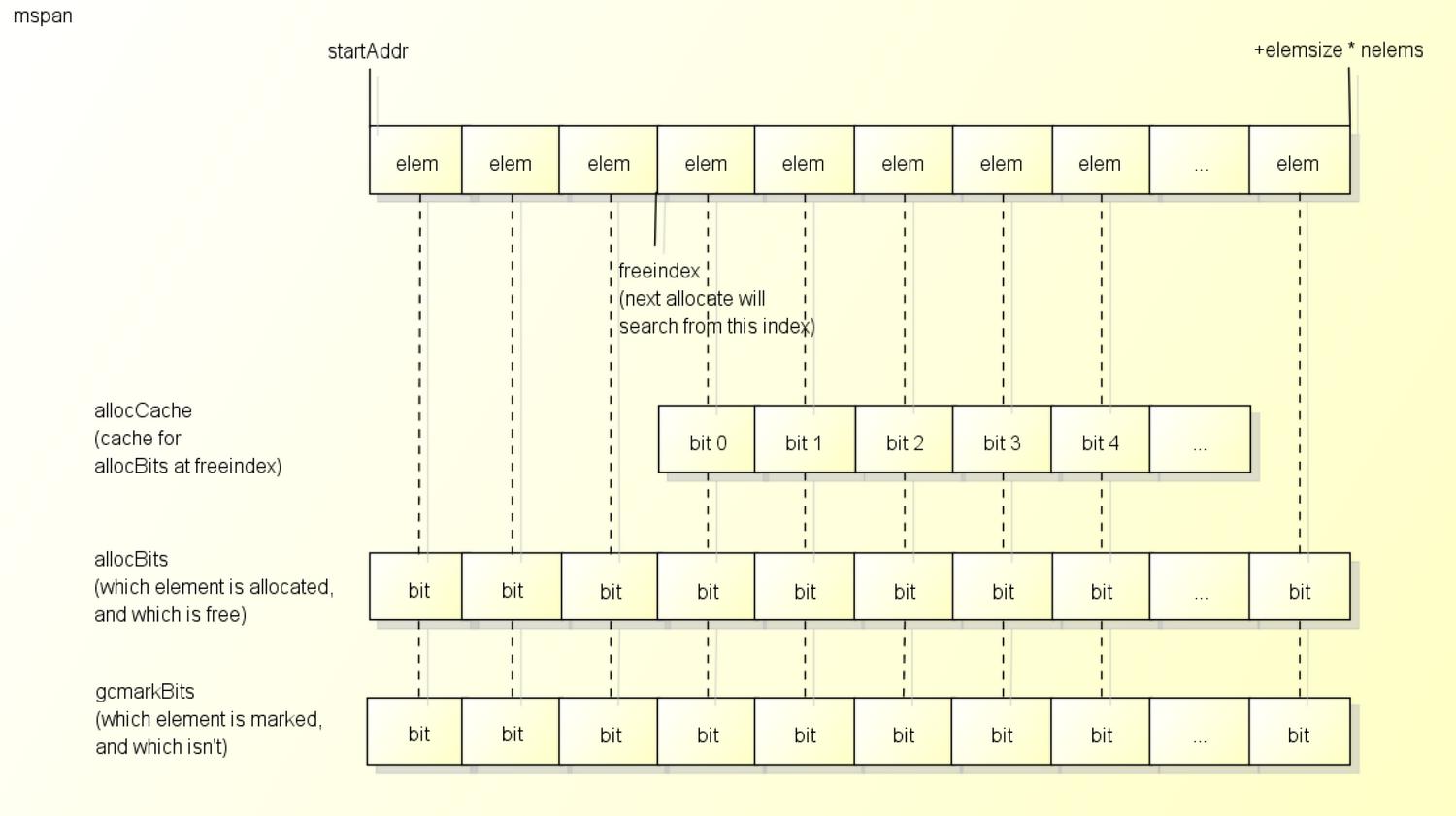
mspan内部结构
go的变量分配在栈和堆是由编译器自动分配的,编译器如果能在编译期间确定变量的生命周期,就会在栈上分配,否则就是逃逸行为,需要在堆上分配内存。分配效率栈大于堆,空间大小堆大于栈。
常见变量逃逸场景:
- 函数返回内部变量的指针
- 发送指针或带有指针的值到 channel 中
- 在一个切片上存储指针或带指针的值
- slice 的背后数组被重新分配了,因为 append 时可能会超出其容量(cap)
- 在 interface 类型上调用方法
- 申请内存容量过大
编译过程进行逃逸分析命令:
# 示例
go build -gcflags="-m" main.go
# 参数-m越多,打印信息越详细
go build -gcflags="-m -m" main.go
垃圾回收 Garbage Collector
内存垃圾类型分为语义垃圾和语法垃圾两种。
语义垃圾(semantic garbage),有的被称作内存泄露,语义垃圾指的是从语法上可达 ( 可以通过局部、全局变量引⽤得到 ) 的对象,但从语义上来讲他们是垃圾,垃圾回收器对此⽆能为⼒。
type a sturct {
}
s:=make([]*a, 10,10)
s=s[:5]
// 后面5个在堆上的内存语义上是应该回收,实际是一直占用内存的
语法垃圾(syntactic garbage),那些从语法上⽆法到达的对象,这些才是垃圾收集器主要的收集⽬标。
func fHeap() {
s := make([]int, 10240)
fmt.Println(s)
}
// 执行完函数,变量s内存会被回收
垃圾回收算法:
- 引用计数 (Reference Counting) :某个对象的根引用计数变为0时,其所有子节点均需被回收。
- 标记压缩 (Mark-Compact) :将存活对象移动到⼀起,解决内存碎片问题。
- 复制算法 (Copying) :将所有正在使⽤的对象从From复制到To空间,堆利用率只有⼀半。
- 标记清扫 (Mark-Sweep) :解决不了内存碎片问题。需要与能尽量避免内存碎片的分配器使用,如tcmalloc,go使用的垃圾回收算法。
触发gc条件:
- 人工runtime.GC
- 需要分配内存时runtime.mallocgc
- 强制gc forcegchelper
三色抽象:
| 颜色 | 说明 |
|---|---|
| ⿊ | 已经扫描完毕,⼦节点扫描完毕,(gcmarkbits = 1,且在队列外) |
| 灰 | 已经扫描完毕,⼦节点未扫描完毕。(gcmarkbits = 1,在队列内) |
| ⽩ | 未扫描,collector不知道任何相关信息,标记结束后被回收的对象 |
具体过程看 https://www.kancloud.cn/aceld/golang/1958308#GC_376
具体过程
垃圾回收以STW作为界限可以分为5个阶段:
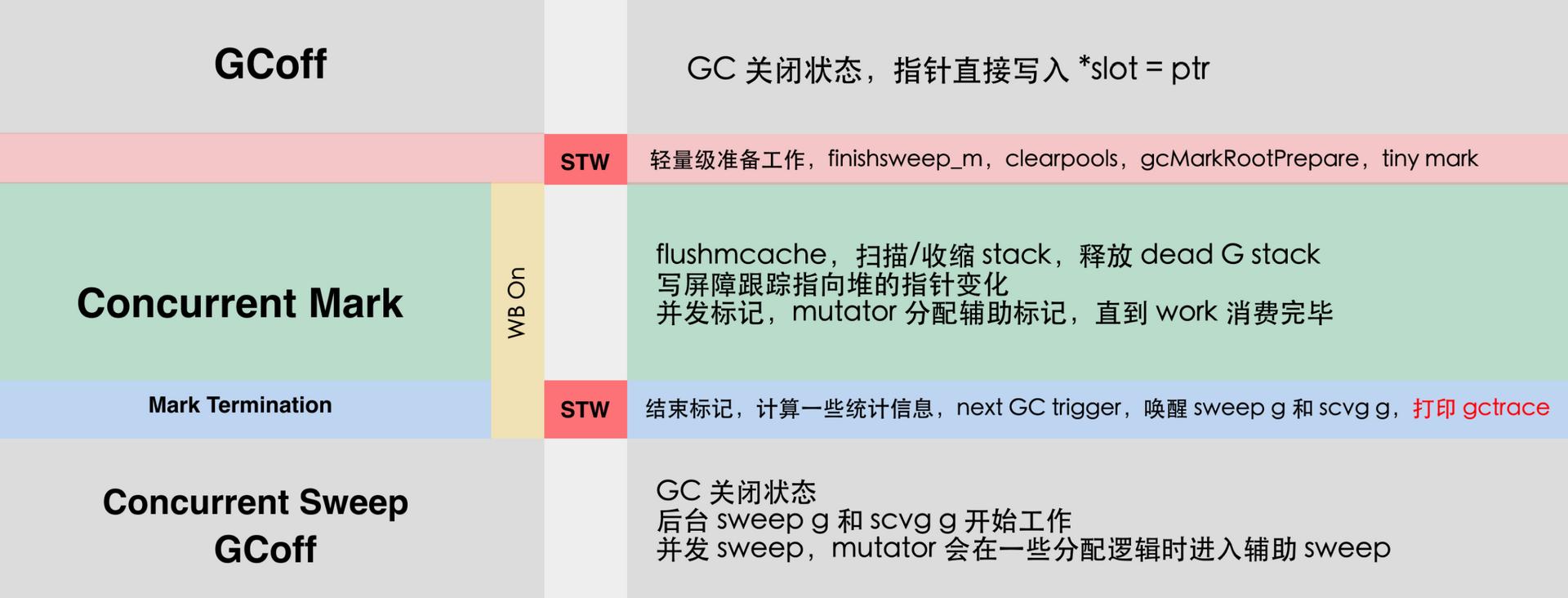
| 阶段 | 说明 | 赋值器状态 |
|---|---|---|
| GCoff | 内存归还阶段,将内存依照策略归还给操作系统,写屏障关闭 | 并发 |
| SweepTermination | 清扫终止阶段,为下一个阶段的并发标记做准备工作,启动写屏障 | STW |
| Mark | 扫描标记阶段,与赋值器并发执行,写屏障开启 | 并发 |
| MarkTermination | 标记终止阶段,保证一个周期内标记任务完成,停止写屏障 | STW |
| GCoff | 内存清扫阶段,将需要回收的内存暂存,写屏障关闭 | 并发 |
写屏障是一个在并发垃圾回收器中才会出现的概念,垃圾回收器的正确性体现在:不应出现对象的丢失,也不应错误的回收还不需要回收的对象。
(1) 标记设置
收集开始时,必须执行的第一个活动是打开写入屏障。写屏障的目的是允许收集器在收集期间保持堆上的数据完整性,因为收集器和应用程序 goroutine 将同时运行。为了打开 Write Barrier,必须停止运行的每个应用程序 goroutine,这个过程时间非常快,平均在10~30微秒内。
(2) 标记
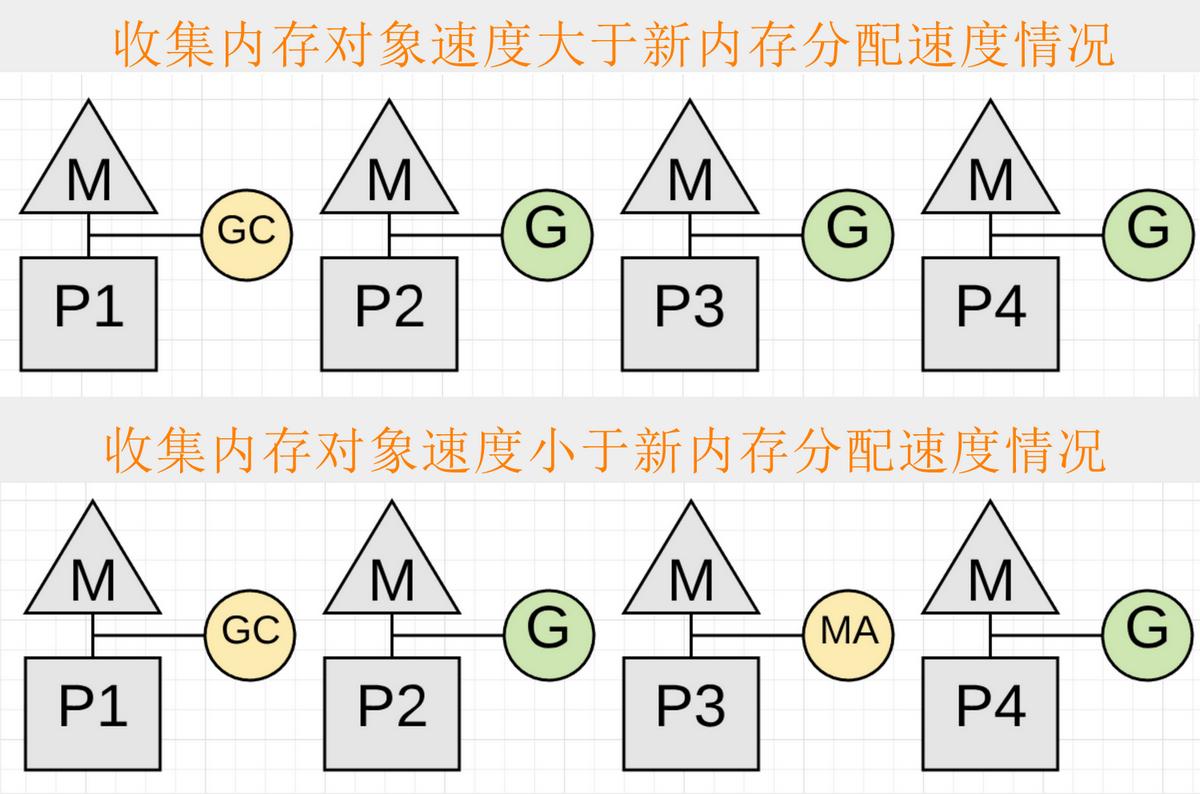
一旦打开写屏障,收集器就会开始标记阶段,收集器做的第一件事就是为自己至少占用25%的可用CPU容量(如果有4个线程,一个用于执行GC),这个阶段用户gc的goroutine和普通goroutine是并发执行的。如果收集内存对象速度赶不上新内存分配速度,收集器把原来执行应用程序 goroutine用来协助标记工作,这称为标记辅助。任何应用程序 Goroutine 被放置在 Mark Assist 中的时间量与它添加到堆内存中的数据量成正比,Mark Assist的作用是助于更快地完成收集。
并发标记,默认所有对象都是白色,使用三色标记法,优先扫描各个goroutine的栈对象,从根节点开始遍历所有对象,将可达的对象标记为黑色,再扫描标记堆对象。
并发扫描标记期间,其他goroutine在栈和堆有可能出现新建对象、对象引用指向变更等场景,有些场景会触发写屏障,写屏障只发生在堆的对象,栈对象的引用改变不会引起屏障触发,因为go是并发运行的,大部分的操作都发生在栈上,成千上万goroutine的栈都进行屏障保护会有性能问题。
场景1:并发扫描标记期间其他goroutine在栈或堆上创建的新对象
这些新建对象统一标记为黑色。
场景2:并发扫描标记期间,一个栈对象(编号1)引用一个堆对象(编号7)
因为对象1是在栈区,不启动写屏障,对象1标记为黑色,后面对象7被扫描到时标记为黑色。
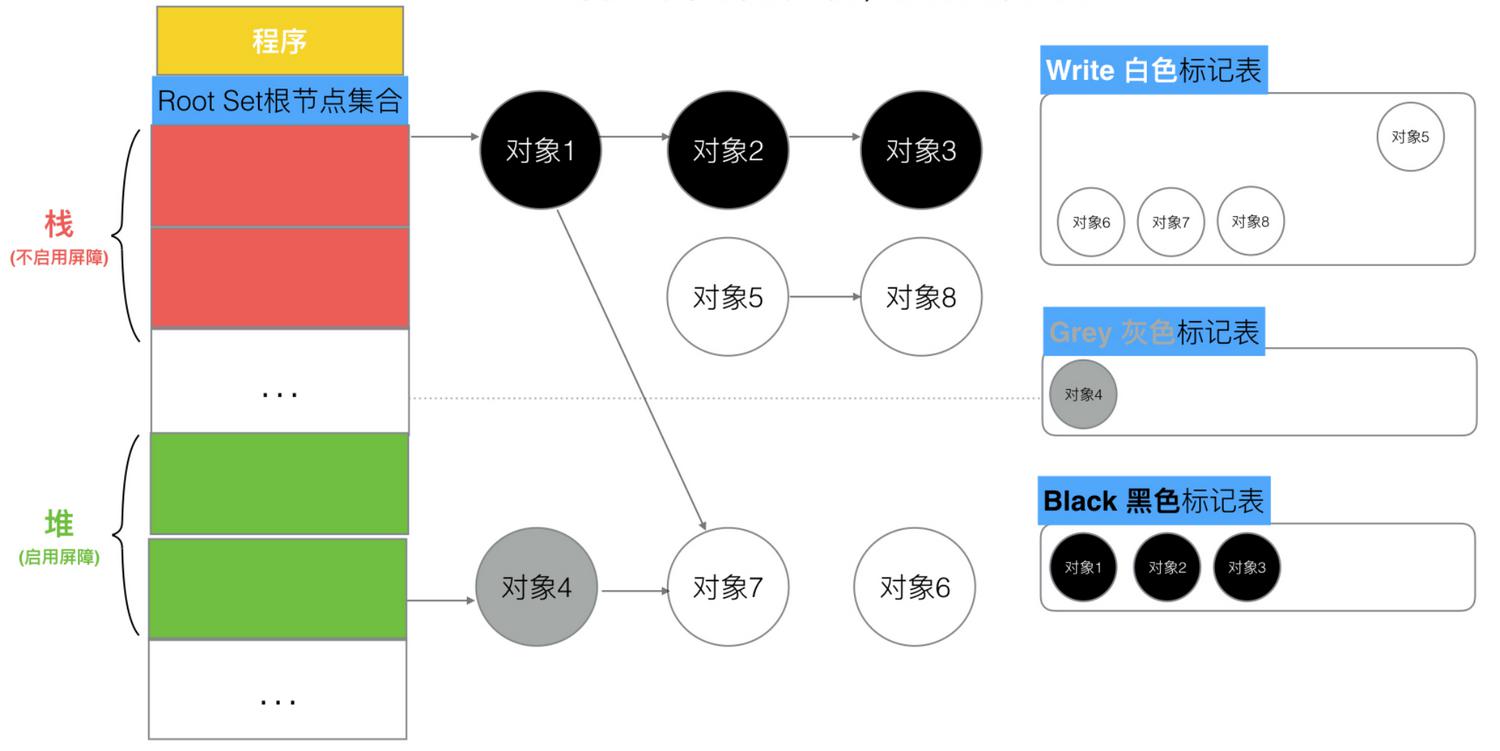
场景3:并发扫描标记期间,一个新建的栈对象(编号9)引用一个栈对象(编号3),同时原来一个栈对象(编号2)删除引用对象(编号3)
因为对象都是在栈区,不会触发写屏障,对象9标记为黑色,后面扫描到对象3时标记为黑色。
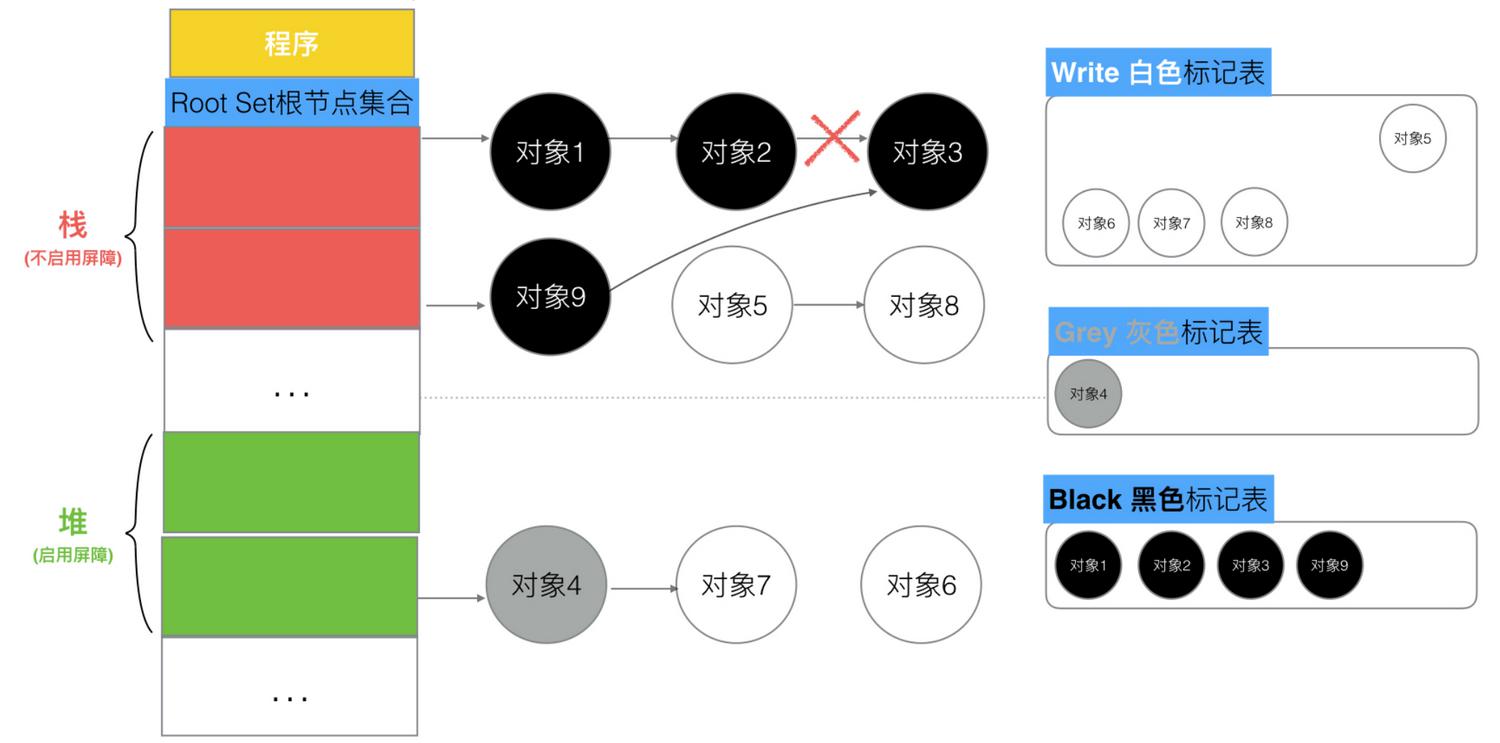
场景4:并发扫描标记期间,一个堆对象(编号10)引用一个堆对象(编号7)
因为是在堆区,会触发写屏障,对象10为黑色,此时对象7标记为灰色,下游对象6被保护,后面扫描到对象7和对象6会时会标记为黑色。
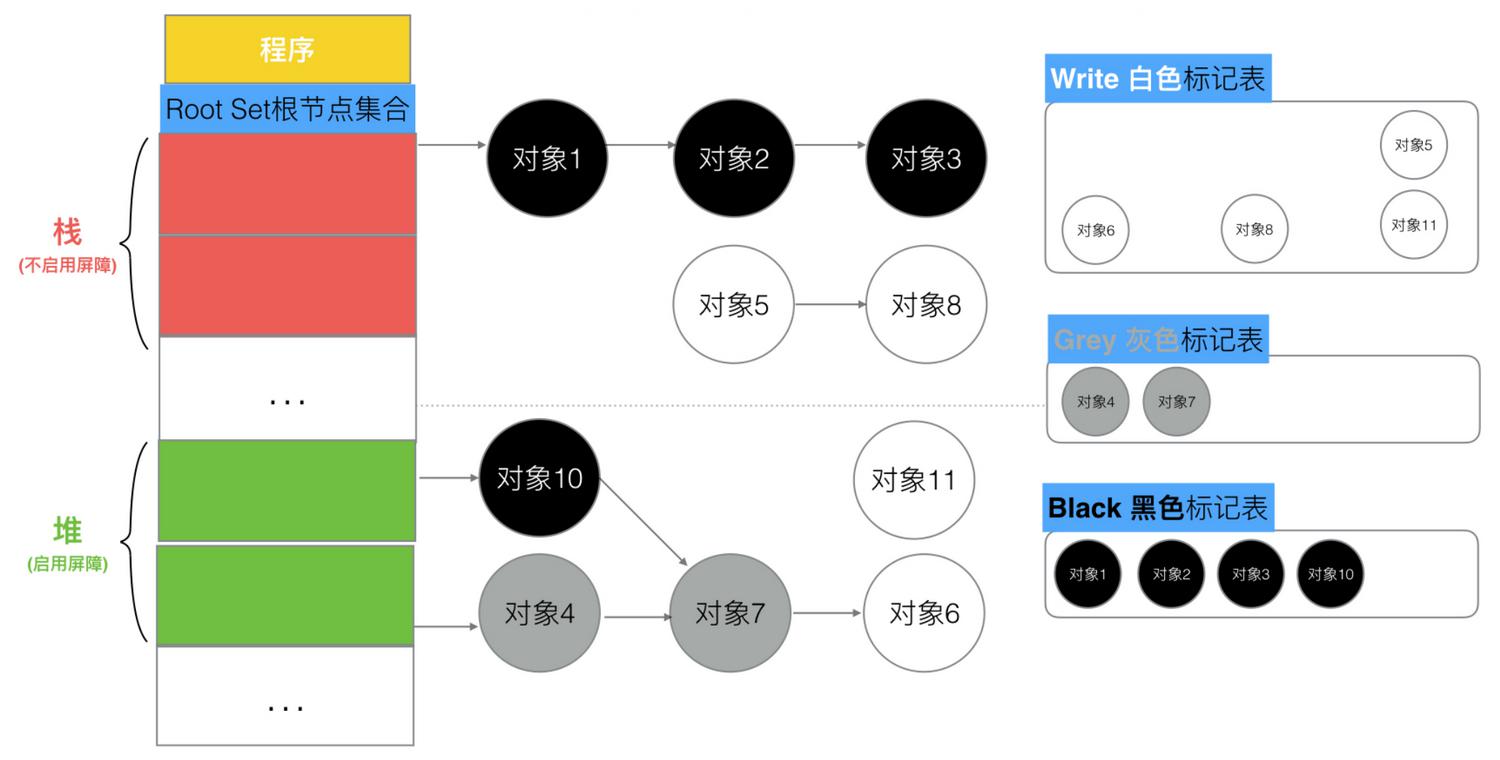
场景5:并发扫描标记期间,一个堆对象(编号4)删除引用堆对象(编号7)
因为对象4是在堆区,会触发写屏障,此时对象7标记为灰色,最终标记为黑色。
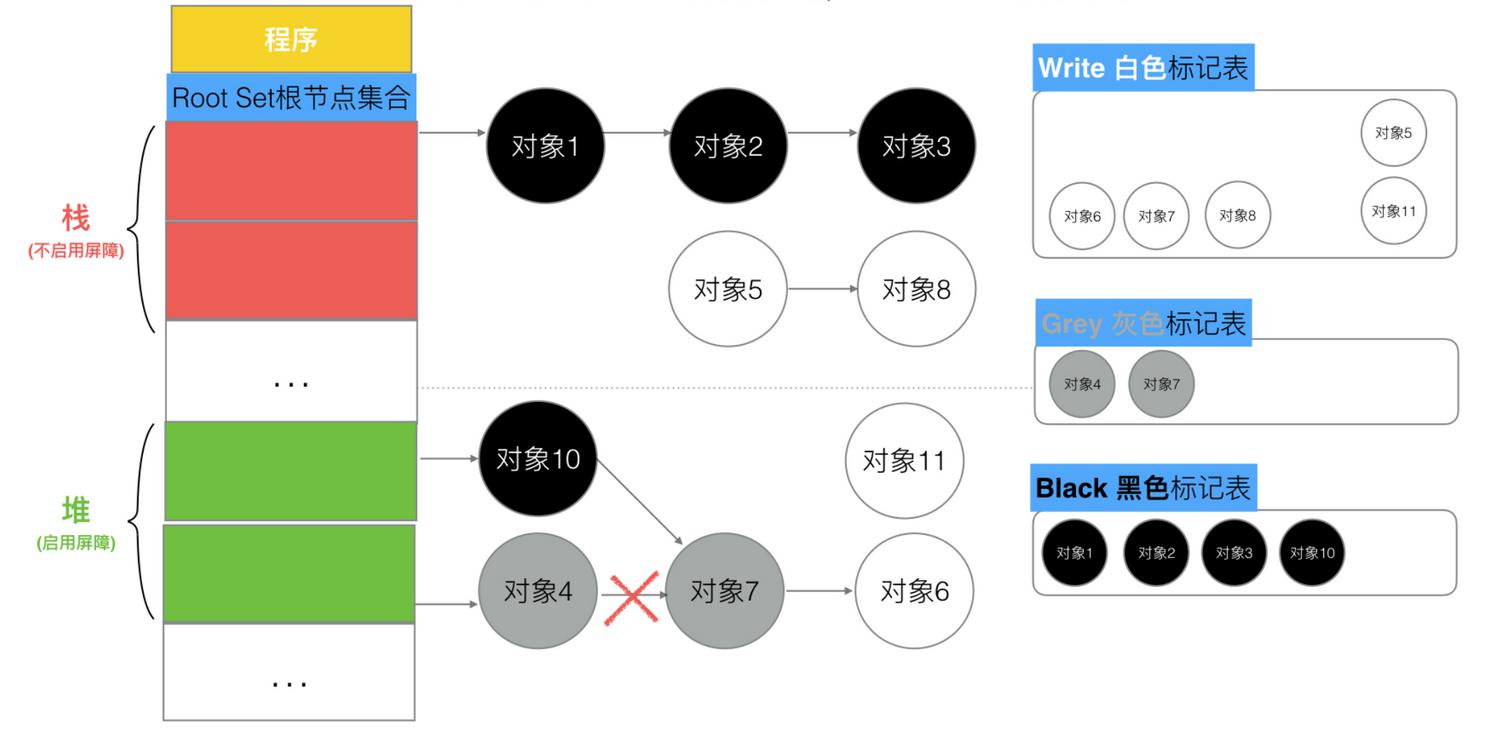
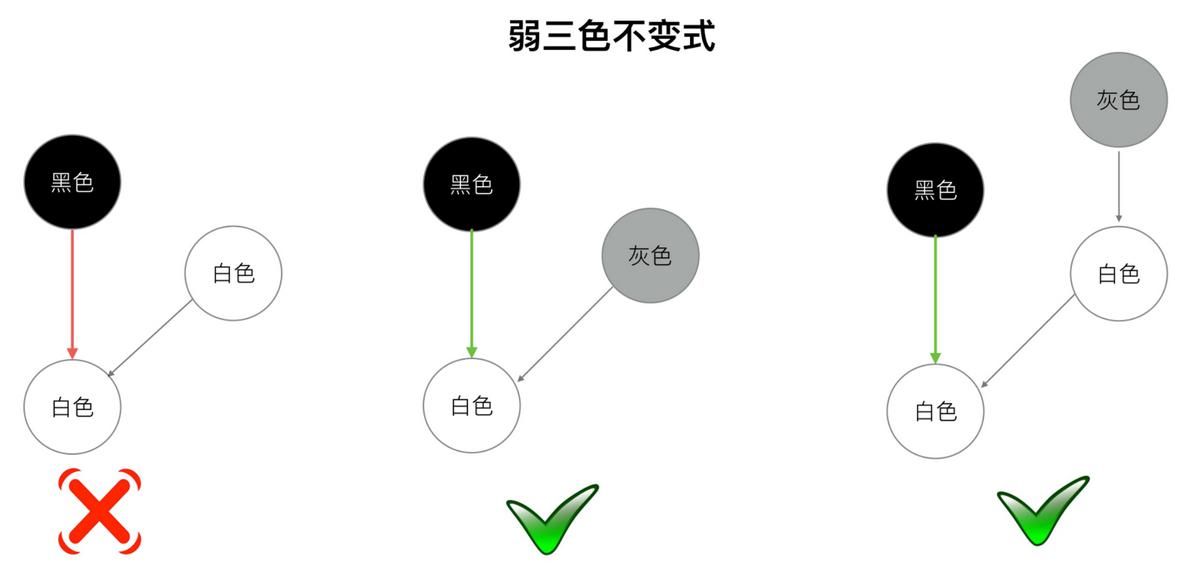
混合写屏障规则:
- GC开始将栈上的对象全部扫描并标记为黑色(之后不再进行第二次重复扫描,无需STW)。
- GC期间,任何在栈上创建的新对象,均为黑色。
- 被删除的对象标记为灰色。
- 被引用的对象标记为灰色。
使用变形的弱三色不变式
(3) 标记终止
标记工作完成后,下一阶段是标记终止。这阶段关闭Write Barrier,执行各种清理任务,计算下一个收集目标的时时间。在标记阶段发现自己处于紧密循环中的 Goroutines 也可能导致标记终止 STW 延迟延长,这个过程时间非常快,平均在60~90微秒内。
(4) 扫除
收集完成后会发生另一个活动叫扫除(sweeping),扫除是指与堆内存中未标记为正在使用的值关联的内存被回收。当应用程序 Goroutine 尝试在堆内存中分配新值时,会发生此活动。
- gcStart –> gcBgMarkWorker && gcRootPrepare,这时gcBgMarkWorker在休眠中
- schedule –> findRunnableGCWorker,唤醒适宜数量的gcBgMarkWorker
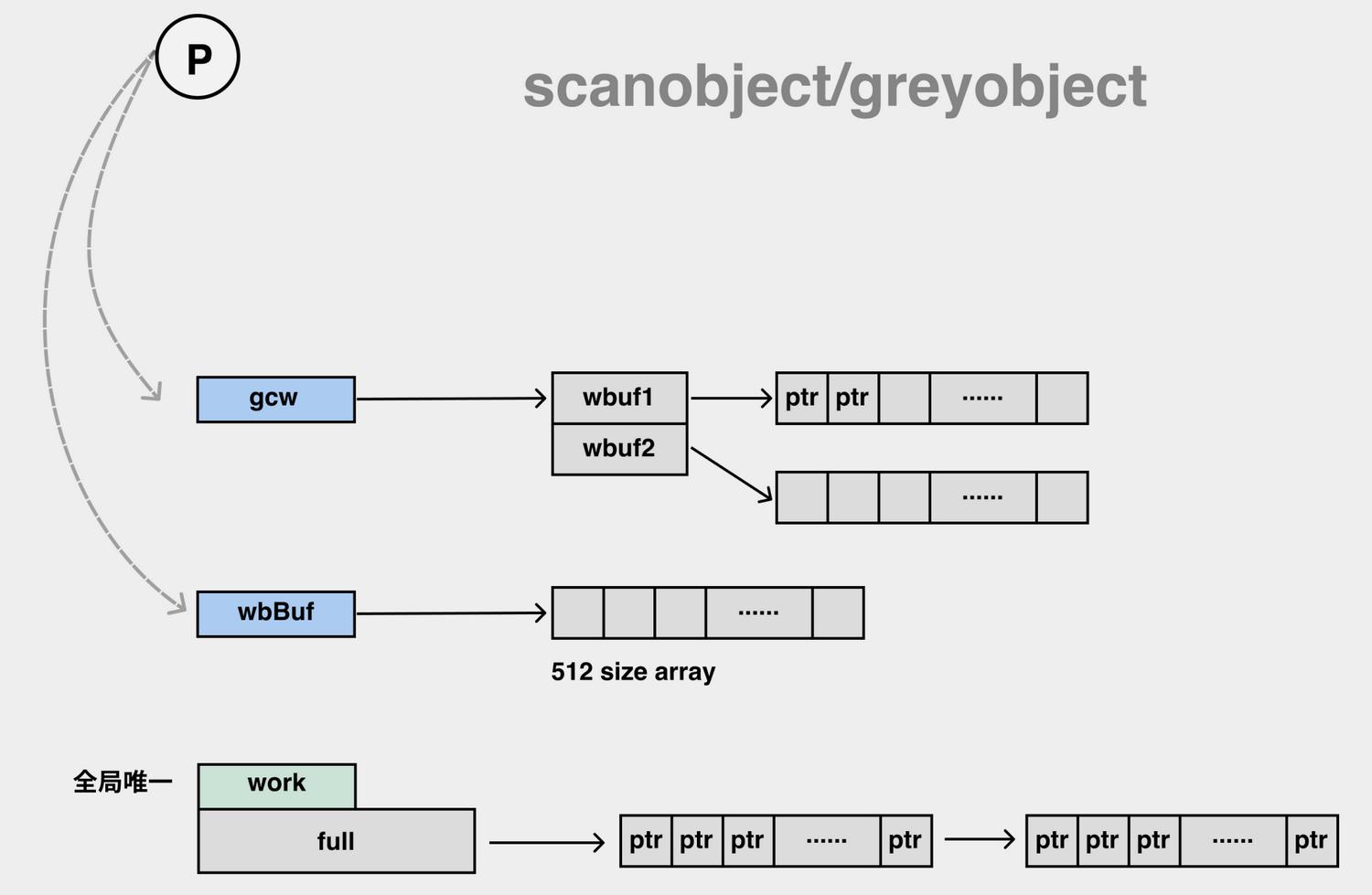
- gcBgMarkWorker –> gcDrain –> scanobject –> greyobject(set mark bit and put to gcw)
- 在 gcBgMarkWorker 中调⽤ gcMarkDone 排空各种 wbBuf 后,使⽤分布式 termination 检查算法,进入gcMarkTermination –> gcSweep 唤醒后台沉睡的 sweepg 和 scvg –> sweep –> wake bgsweep && bgscavenge
Golang各个版本垃圾回收区别:
GoV1.3 普通标记清除法,整体过程需要启动STW,效率极低。
GoV1.5 三色标记法, 堆空间启动写屏障,栈空间不启动,全部扫描之后,需要重新扫描一次栈(需要STW),效率普通
GoV1.8 三色标记法,混合写屏障机制, 栈空间不启动,堆空间启动,整个过程几乎不需要STW,效率较高。
GC跟踪
在运行任何 Go 应用程序时,可以通过GODEBUG在选项中包含环境变量来生成 GC 跟踪。gctrace=1每次发生收集时,运行时都会将 GC 跟踪信息写入stderr.
# 示例
GODEBUG=gctrace=1 ./app
gc 1405 @6.068s 11%: 0.058+1.2+0.083 ms clock, 0.70+2.5/1.5/0+0.99 ms cpu, 7->11->6 MB, 10 MB goal, 12 P
各个值的含义:
// General
gc 65 : 自程序开始以来运行了65次GC
@6.068s : 程序开始后的6秒
11% : 到目前为止,有11%的可用CPU被用在了GC上
// Wall-Clock
0.058ms : STW : 标记开始,打开写屏障
1.2ms : Concurrent : 标记时间
0.083ms : STW : 标记终止,写入障碍物关闭和清理
// CPU Time
0.70ms : STW : 标记开始
2.5ms : Concurrent : 标记-辅助时间(GC与分配一致)
1.5ms : Concurrent : 标记 - 背景GC时间
0ms : Concurrent : 标记 - 闲置的GC时间
0.99ms : STW : 标记终止
// Memory
7MB : 记开始前使用的堆内存
11MB : 标记结束后使用中的堆内存
6MB : 标记结束后,堆内存被标记为活的
10MB : 标记结束后,堆内存的收集目标是使用中的
// Threads
12P : 用于运行Goroutines的逻辑处理器或线程的数量
上面是在日志打印每次垃圾回收数据,不够直观,可以使用go tool trace命令,通过图形化界面查看程序生命周期内的所有协程执行过程(包括gc过程)。
(1) 首先在程序中插入跟踪程序代码:
// 在程序当前目录生成trace.out文件
type Trace struct {
F *os.File
}
func (t *Trace) Start() {
var err error
t.F, err = os.Create("trace.out")
if err != nil {
panic(err)
}
err = trace.Start(t.F)
if err != nil {
panic(err)
}
}
func (t *Trace) Stop() {
trace.Stop()
t.F.Close()
}
func main() {
tr := &Trace{}
tr.Start()
defer tr.Stop()
// 你的程序
}
(2) 执行你的程序代码,等待程序正常结束,在程序当前目录下生成trace.out
(3) 查看程序跟踪信息
go tool trace trace.out
在浏览器显示支持跟踪类型
- View trace
- Goroutine analysis
- Network blocking profile (⬇)
- Synchronization blocking profile (⬇)
- Syscall blocking profile (⬇)
- Scheduler latency profile (⬇)
- User-defined tasks
- User-defined regions
- Minimum mutator utilization
点击第一个View trace,选中小控制面板的zoom,在指定位置点击鼠标左键网上拖动放大细节,如下图所示:
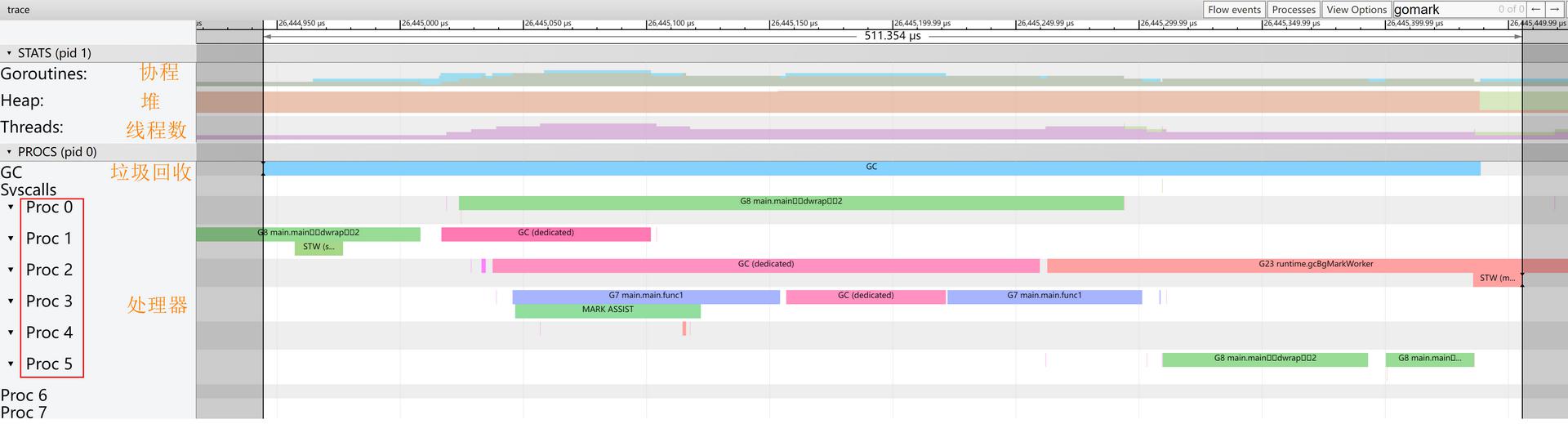
从图中可以看出,在垃圾回收阶段,处理器1和处理器2是专门用来给收集器收集对象,其中处理器3也会辅助标记,使得更快的完成收集,并发收集对象过程中也有用户程序在执行,同时看到在垃圾回收这个过程出现两次STW。
在垃圾收集启动期间,运行时会调用 runtime.gcBgMarkStartWorkers 为全局每个处理器创建用于执行后台标记任务的 Goroutine,每一个 Goroutine 都会运行 runtime.gcBgMarkWorker,所有运行 runtime.gcBgMarkWorker 的Goroutine在启动后都会陷入休眠等待调度器的唤醒。一般情况下此函数不会占用这么多的 cpu,出现这种情况一般都是内存 gc 问题,如果分配对象的数量非常多,采集器来不及采集对象,就会唤醒runtime.gcBgMarkWorker的goroutine进行台标记。
参考:
- Go 中的垃圾回收 https://www.ardanlabs.com/blog/2018/12/garbage-collection-in-go-part1-semantics.html
- Golang三色标记+混合写屏障GC模式全分析 https://www.kancloud.cn/aceld/golang/1958308#GC_376
- go tool trace https://making.pusher.com/go-tool-trace/
- 揭秘 Golang 内存管理优化 https://cdmana.com/2021/10/20211031083312698S.html
- 垃圾收集器 https://draveness.me/golang/docs/part3-runtime/ch07-memory/golang-garbage-collector/
专题「golang相关」的其它文章 »
- DeepSeek与Sponge黄金组合打造后端高效开发新范式 (Feb 09, 2025)
- 使用开发框架sponge快速把单体web服务拆分为微服务 (Sep 18, 2023)
- 使用开发框架sponge一天多开发完成一个简单版社区后端服务 (Jul 30, 2023)
- 一个强大的Go开发框架sponge,以低代码方式开发项目 (Jan 06, 2023)
- go test命令 (Apr 15, 2022)
- go应用程序性能分析 (Mar 29, 2022)
- channel原理和应用 (Mar 22, 2022)
- go调试工具 (Mar 13, 2022)
- cobra基础与实践 (Mar 10, 2022)
- grpc基础与实践 (Nov 27, 2020)
- 配置文件viper库 (Nov 22, 2020)
- 根据服务名称查看golang程序的profile信息 (Sep 03, 2019)
- go语言开发规范 (Aug 28, 2019)
- goroutine和channel应用——处理队列 (Sep 06, 2018)
- golang中的context包 (Aug 28, 2018)